附视频链接: 天善智能Kaggle十大案例精讲(连载中) 提供案例代码和数据,可以实操。欢迎学习!(数据集和代码在链接公告处提供下载)
2017年8月26日,全球最大的数据科学社群Kaggle发布了数据科学/机器学习业界现状全行业调查的数据集。调查问卷数据从2017年8月7日~8月25日收集。受访者囊括了来自50多个国家的16,716+位从业者,根据kaggle的调查问卷数据集,我们挖掘一些有营养的信息。
################# =========== 导入数据+简单清洗 ============== #################
library(data.table) # fread()
library(dplyr) # group_by() / %>% / summaries()
library(ggplot2) # ggplot()
responses = fread("D:/R/天善智能/书豪十大案例/数据科学调查\\multipleChoiceResponses.csv")
## 把Country列中的表示中国的特征值改为中国
responses$Country <- ifelse(responses$Country == "Republic of China" |
responses$Country == "People 's Republic of China",
"China", responses$Country)


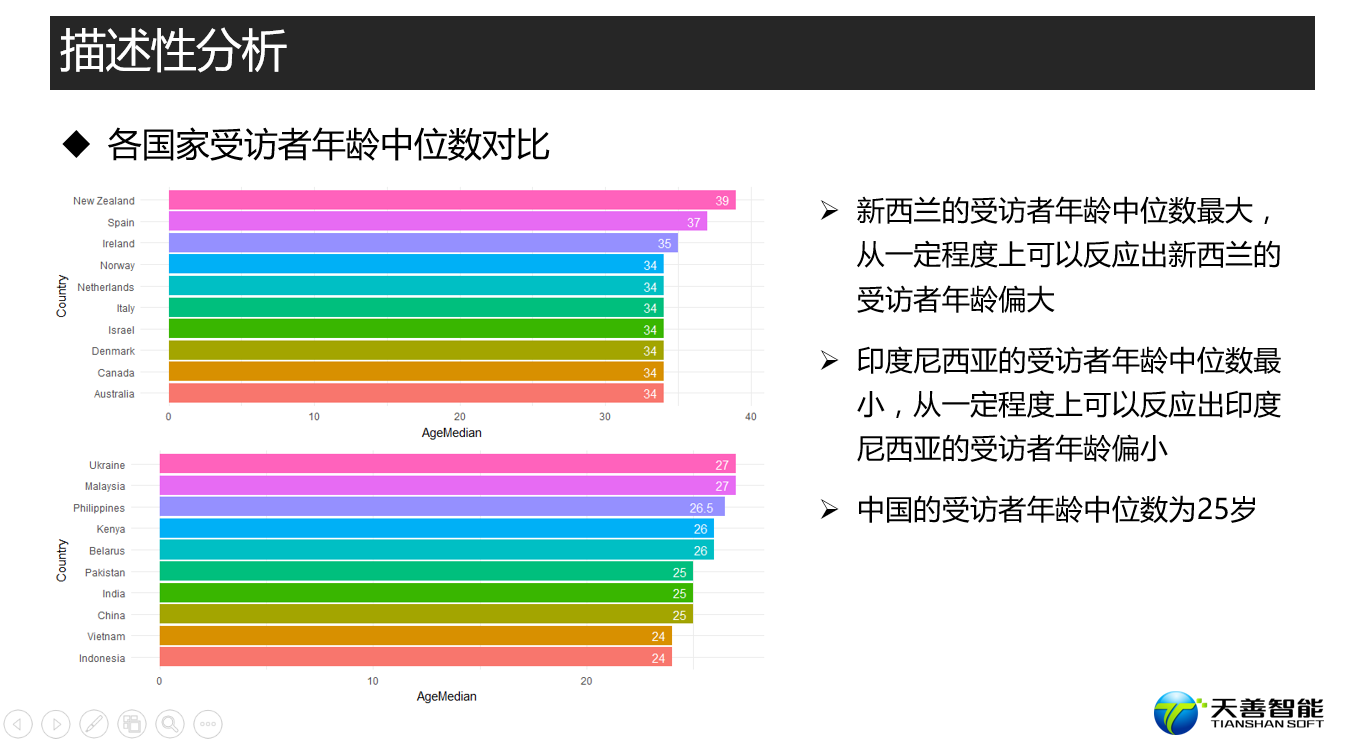
################# =========== 国家+年龄统计 ================ ##################
## 探索数据科学从业者的年龄中位数最大的十个国家
# 创建绘图所需的数据源(按照Country进行统计Age的中位数,并且按照Age进行降序排列)
df_country_age <- responses %>%
group_by(Country) %>% # 按照Country进行统计
summarise(AgeMedian = median(Age, na.rm = T)) %>% # 统计Age的中位数
arrange(desc(AgeMedian)) # 按照Age进行降序排列
# reorder(Country, AgeMedian)--按照AgeMedian的升序排列其对应的Country
# head(df_country, 10)--选取数据源的前10行
# x参数中传入图中的x轴所需数据,y参数同理
# geom_bar()--绘制条形图的子函数
# fill = Country--按照Country填充条形图颜色
# stat(统计转换)参数设置为'identity',即对原始数据集不作任何统计变换
# geom_text()--添加文本注释的子函数
# label = AgeMedian--添加AgeMedian中的内容
# hjust--控制横向对齐(0:底部对齐, 0.5:居中, 1:顶部对齐)
# colour--控制注释颜色
# theme_minimal()--是ggplot的一种主背景主题
ggplot(head(df_country_age, 10), aes(x = reorder(Country, AgeMedian), y = AgeMedian)) +
geom_bar(aes(fill = Country), stat = 'identity') +
labs(x = 'Country', y = 'AgeMedian') +
geom_text(aes(label = AgeMedian), hjust = 1.5, colour = 'white') +
coord_flip() +
theme_minimal() +
theme(legend.position = 'none') # 移除图例
# 封装绘图函数
fun1 <- function(data, xlab, ylab, xname, yname) {
ggplot(data, aes(xlab, ylab)) +
geom_bar(aes(fill = xlab), stat = 'identity') +
labs(x = xname, y = yname) +
geom_text(aes(label = ylab), hjust = 1.5, colour = 'white') +
coord_flip() +
theme_minimal() +
theme(legend.position = 'none')
}
data <- head(df_country_age, 10)
xname <- 'Country'
yname <- 'AgeMedian'
fun1(data, reorder(data$Country, data$AgeMedian), data$AgeMedian, xname, yname)
## 探索数据科学从业者的年龄中位数最小的十个国家
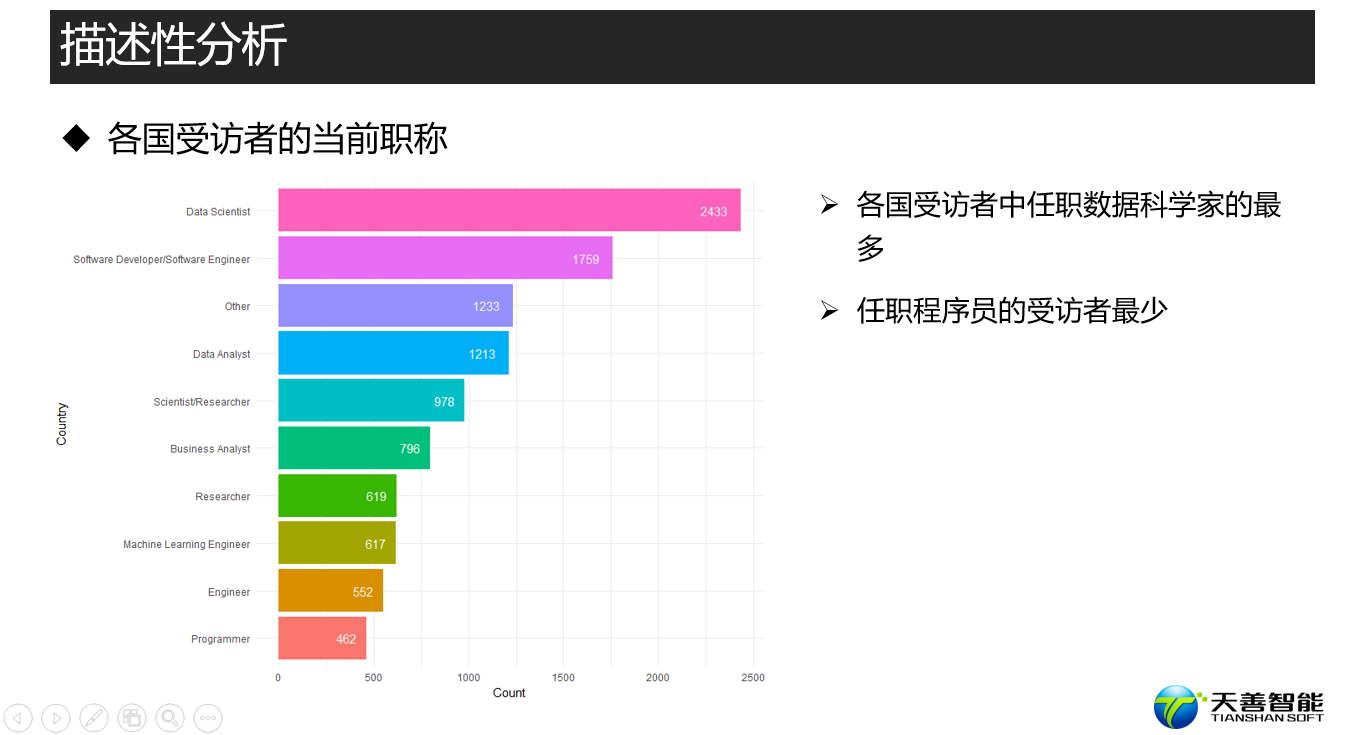
################# =========== 职位统计 ==================== ####################
## 探索kaggler的当前职位
# 创建绘图所需的数据源(按照CurrentJobTitleSelect统计其个数,并按照个数进行降序排列)
df_CJT <- responses %>%
filter(CurrentJobTitleSelect != '') %>% # 筛选CurrentJobTitleSelect不为空的观测
group_by(CurrentJobTitleSelect) %>% # 按照CurrentJobTitleSelect统计
summarise(Count = n()) %>% # 统计其特征值的个数(Count)
arrange(desc(Count)) # 按照个数(Count)进行降序排列
data <- head(df_CJT, 10)
xname <- 'Country'
yname <- 'Count'
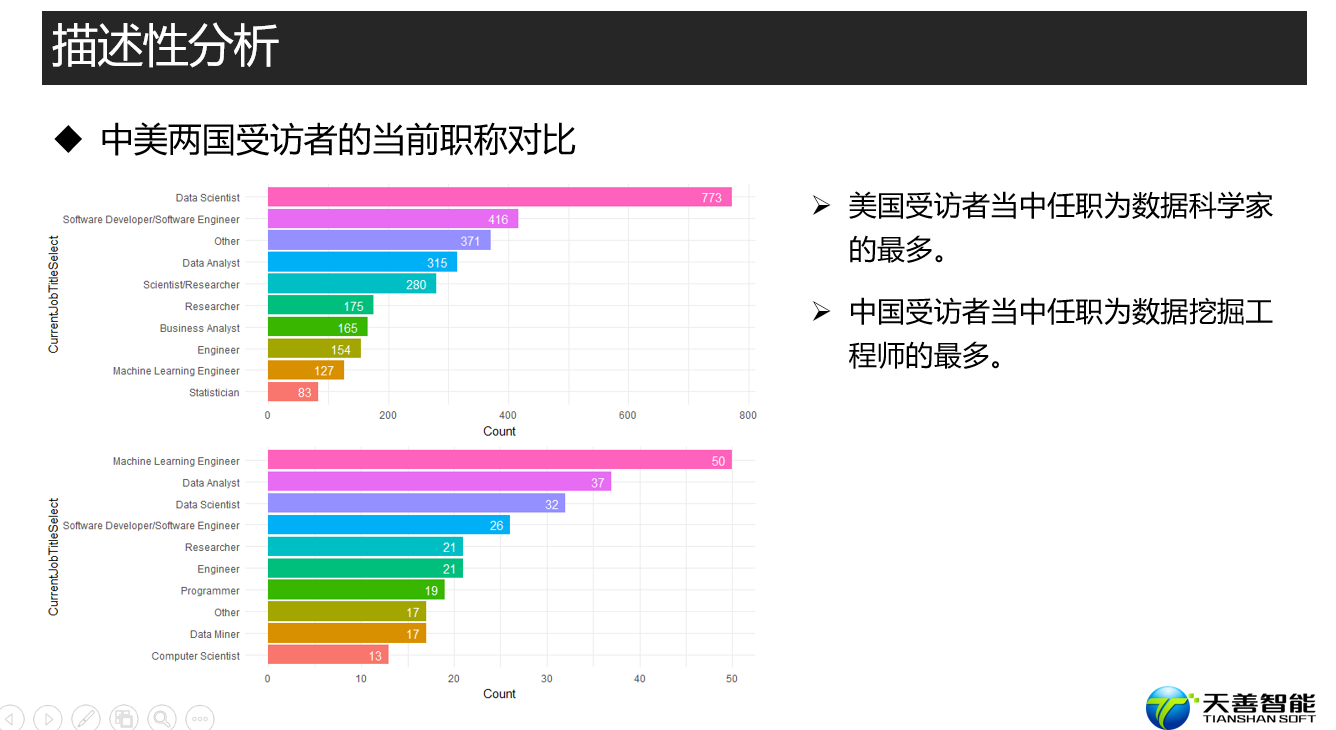
fun1(data, reorder(data$CurrentJobTitleSelect, data$Count), data$Count, xname, yname)
## 探索美国kaggler的当前职位
# 创建绘图所需的数据源(按照CurrentJobTitleSelect统计其个数,并按照个数进行降序排列)
df_CJT_USA <- responses %>%
# 筛选CurrentJobTitleSelect不为空且美国kaggler的观测
filter(CurrentJobTitleSelect != '' & Country == 'United States') %>%
group_by(CurrentJobTitleSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_CJT_USA, 10)
xname <- 'CurrentJobTitleSelect'
yname <- 'Count'
fun1(data, reorder(data$CurrentJobTitleSelect, data$Count), data$Count, xname, yname)
## 探索中国kaggler的当前职位
df_CJT_China <- responses %>%
filter(CurrentJobTitleSelect != '' & Country == 'China') %>%
group_by(CurrentJobTitleSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_CJT_China, 10)
xname <- 'CurrentJobTitleSelect'
yname <- 'Count'
fun1(data, reorder(data$CurrentJobTitleSelect, data$Count), data$Count, xname, yname)
################# =========== 明年将学习的机器学习工具 ============== ##########
## 探索kaggler明年将学习的机器学习工具
# 创建绘图所需数据源(按照MLToolNextYearSelect统计其个数,比按照其个数降序排列)
df_MLT <- responses %>%
filter(MLToolNextYearSelect != '') %>% # 筛选出MLToolNextYearSelect不为空的观测
group_by(MLToolNextYearSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_MLT, 10)
xname <- 'ML Tool'
yname <- 'Count'
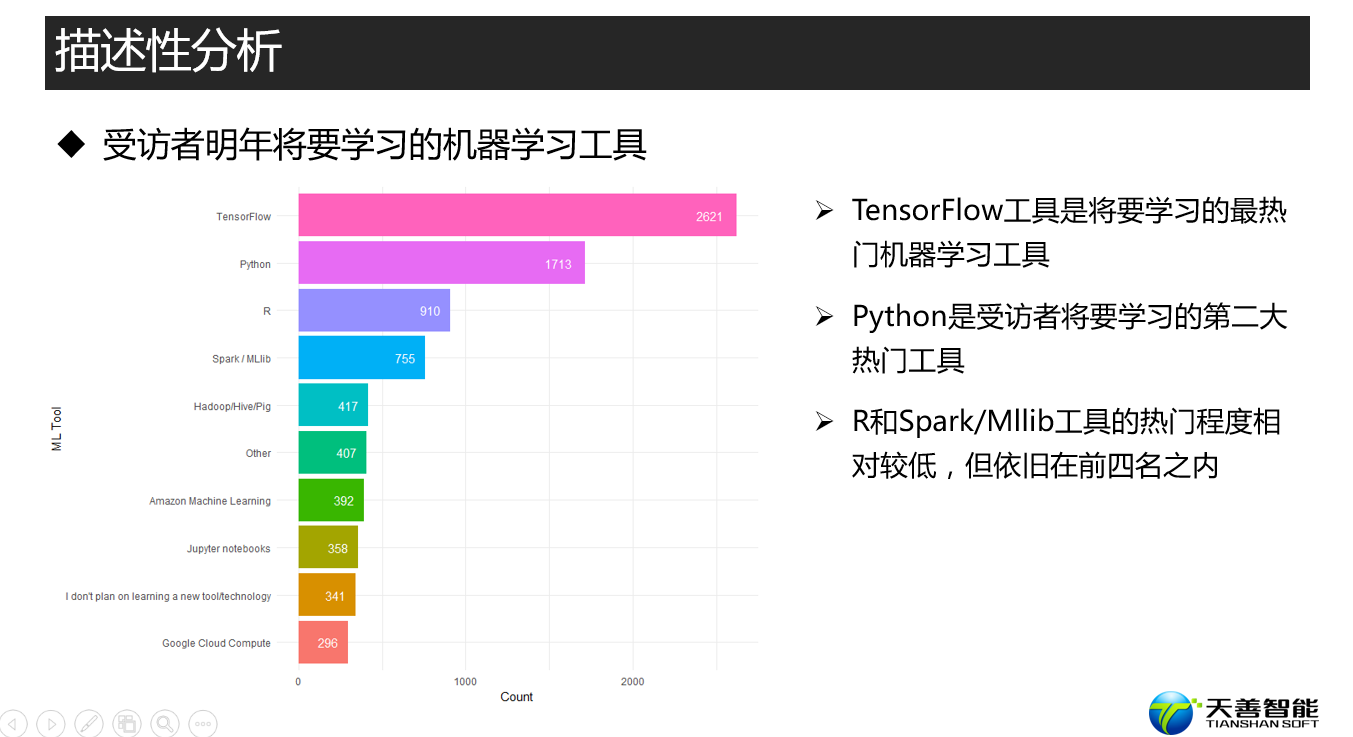
fun1(data, reorder(data$MLToolNextYearSelect, data$Count), data$Count, xname, yname)
## 探索美国kaggler明年将学习的机器学习工具
# 创建绘图所需数据源(按照MLToolNextYearSelect统计其个数,比按照其个数降序排列)
df_MLT_USA <- responses %>%
# 筛选出MLToolNextYearSelect不为空且美国kaggler的观测
filter(MLToolNextYearSelect != '' & Country == 'United States') %>%
group_by(MLToolNextYearSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_MLT_USA, 10)
xname <- 'ML Tool'
yname <- 'Count'
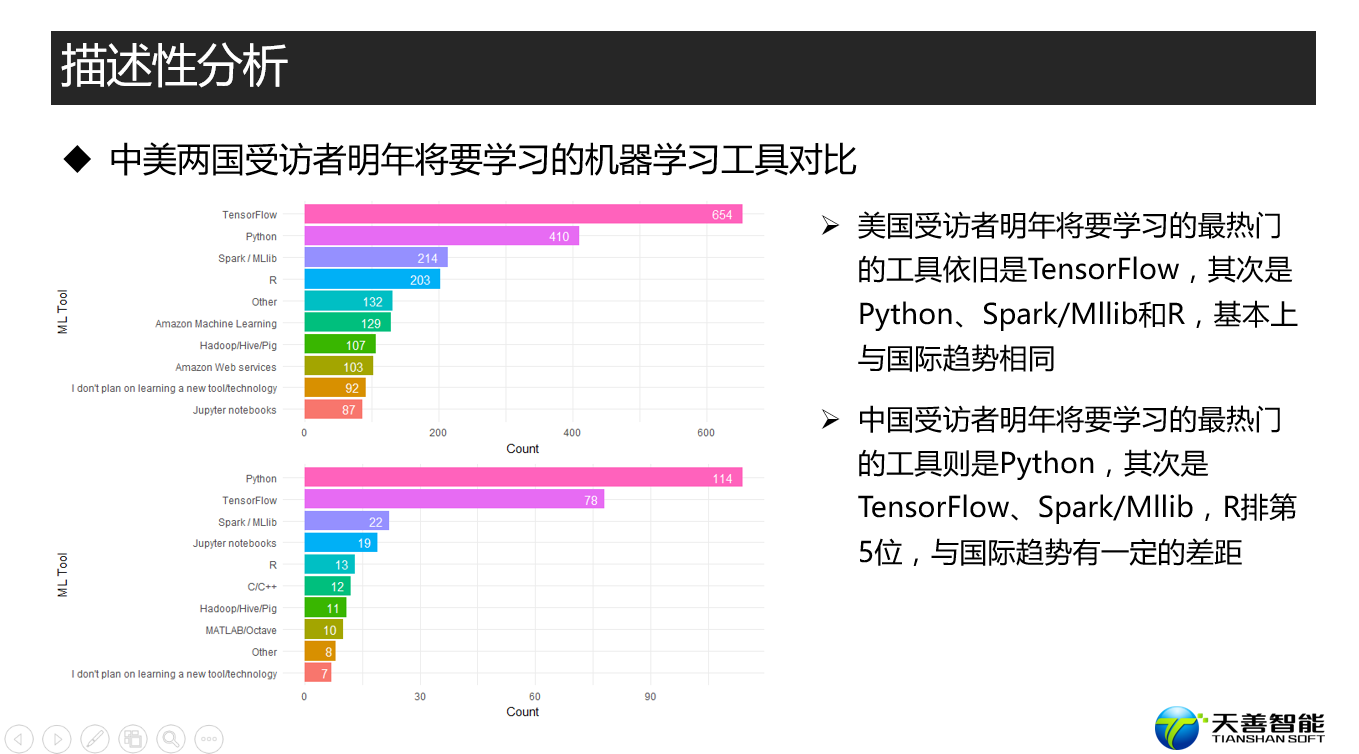
fun1(data, reorder(data$MLToolNextYearSelect, data$Count), data$Count, xname, yname)
## 探索中国kaggler明年将学习的机器学习工具
# 创建绘图所需数据源(按照MLToolNextYearSelect统计其个数,比按照其个数降序排列)
df_MLT_China <- responses %>%
# 筛选出MLToolNextYearSelect不为空且中国kaggler的观测
filter(MLToolNextYearSelect != '' & Country == 'China') %>%
group_by(MLToolNextYearSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_MLT_China, 10)
xname <- 'ML Tool'
yname <- 'Count'
fun1(data, reorder(data$MLToolNextYearSelect, data$Count), data$Count, xname, yname)
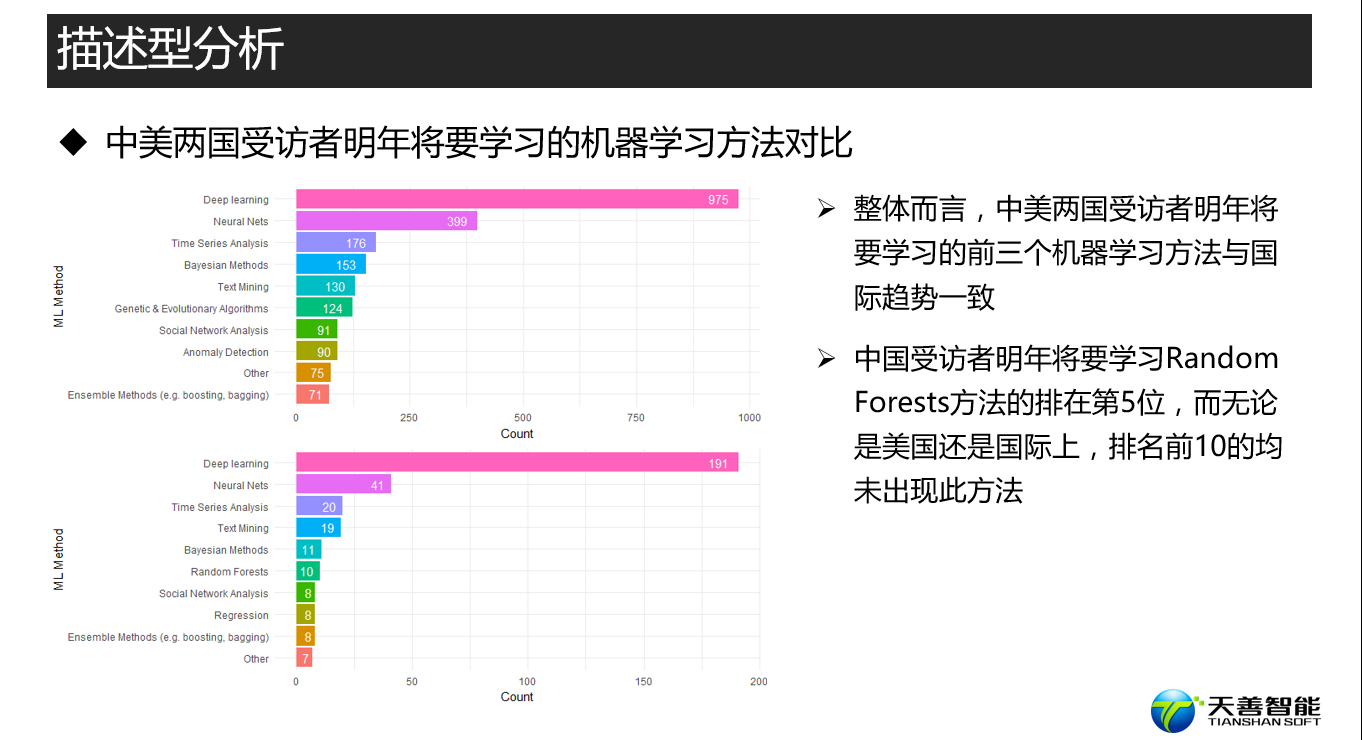
################# =========== 明年将学习的机器学习方法 ============= ###########
## 探索kaggler明年将学习的机器学习方法
# 创建绘图所需数据源(按照MLMethodNextYearSelect统计其个数,比按照其个数降序排列)
df_MLM <- responses %>%
filter(MLMethodNextYearSelect != '') %>% # 筛选MLMethodNextYearSelect不为空的观测
group_by(MLMethodNextYearSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_MLM, 10)
xname <- 'ML Method'
yname <- 'Count'
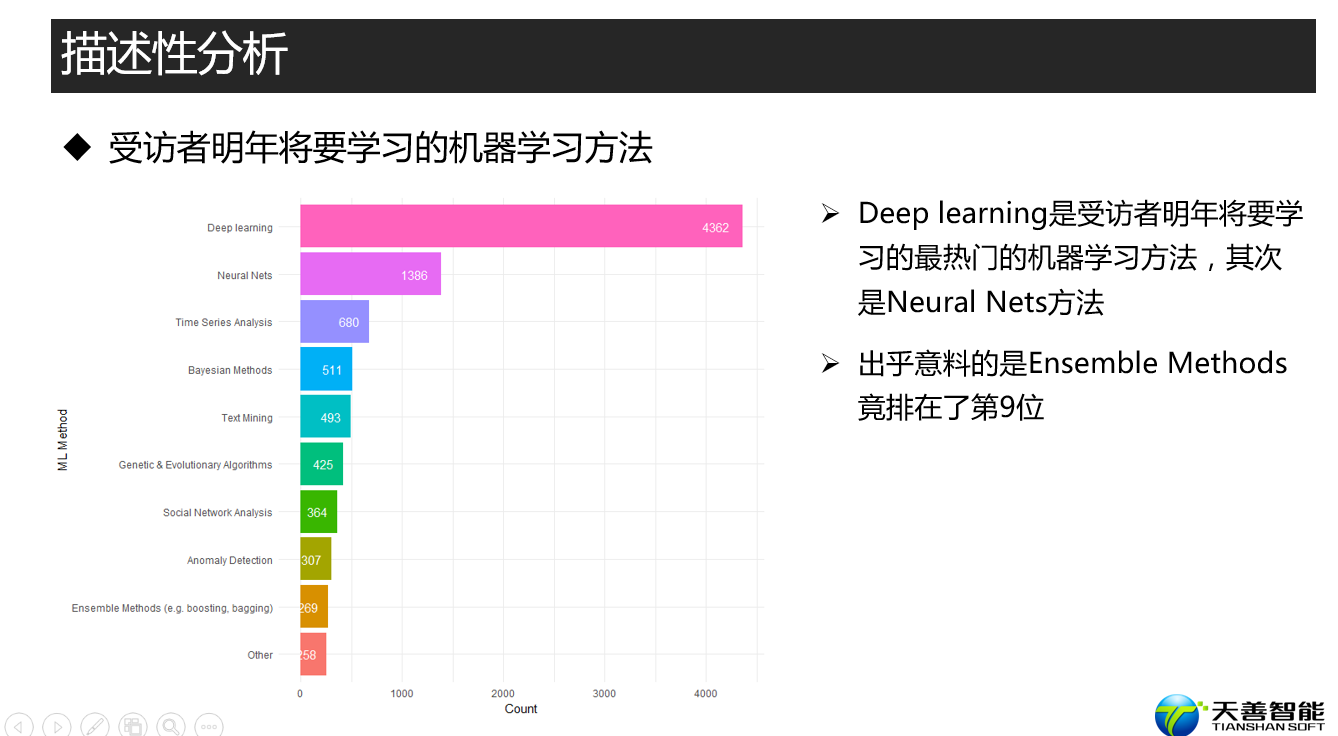
fun1(data, reorder(data$MLMethodNextYearSelect, data$Count), data$Count, xname, yname)
## 探索美国kaggler明年将学习的机器学习方法
# 创建绘图所需数据源(按照MLMethodNextYearSelect统计其个数,比按照其个数降序排列)
df_MLM_USA <- responses %>%
# 筛选MLMethodNextYearSelect不为空且美国kaggler的观测
filter(MLMethodNextYearSelect != '' & Country == 'United States') %>%
group_by(MLMethodNextYearSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_MLM_USA, 10)
xname <- 'ML Method'
yname <- 'Count'
fun1(data, reorder(data$MLMethodNextYearSelect, data$Count), data$Count, xname, yname)
## 探索中国kaggler明年将学习的机器学习方法
# 创建绘图所需数据源(按照MLMethodNextYearSelect统计其个数,比按照其个数降序排列)
df_MLM_China <- responses %>%
# 筛选MLMethodNextYearSelect不为空且中国kaggler的观测
filter(MLMethodNextYearSelect != '' & Country == 'China') %>%
group_by(MLMethodNextYearSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_MLM_China, 10)
xname <- 'ML Method'
yname <- 'Count'
fun1(data, reorder(data$MLMethodNextYearSelect, data$Count), data$Count, xname, yname)
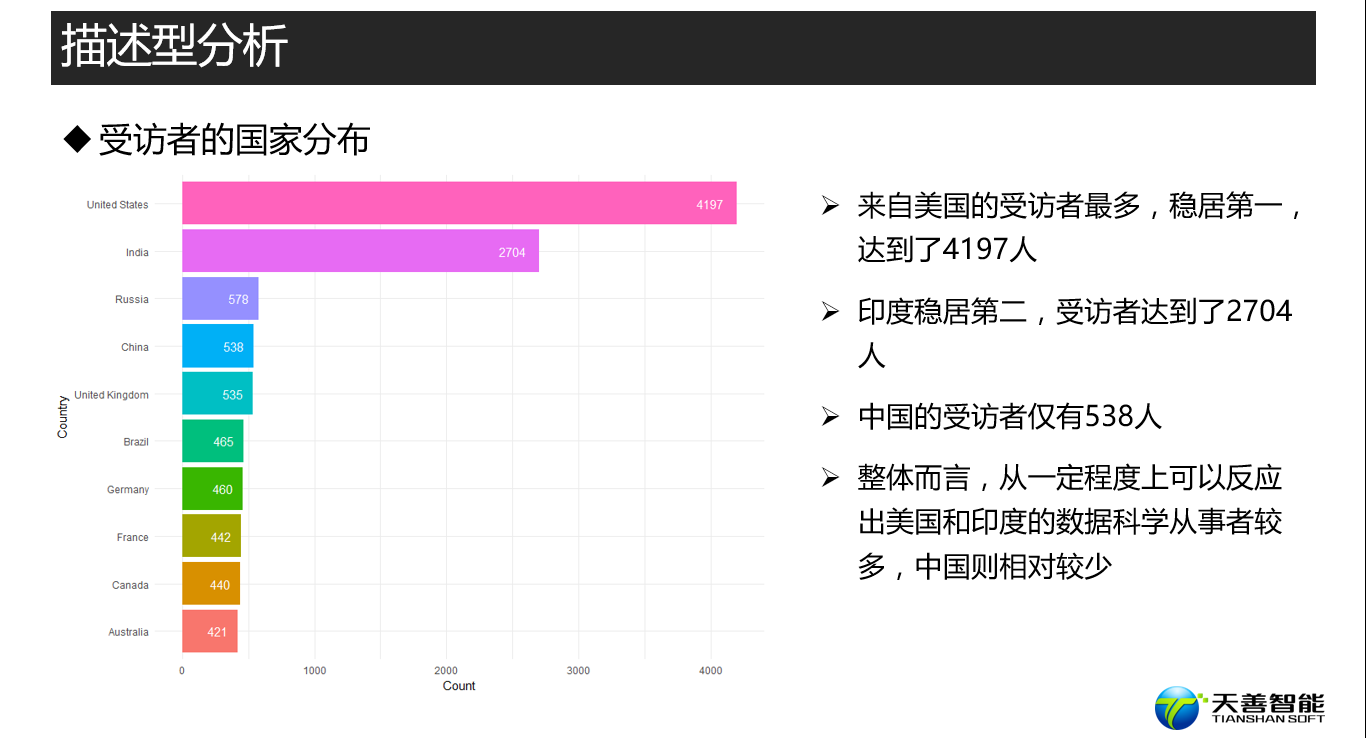
################# =========== 受访者来自的国家 ============= #################
## 探索kaggler都来自哪些国家
# 创建绘图所需数据源(按照Country统计其个数,比按照其个数降序排列)
df_Country <- responses %>%
filter(Country != '' & Country != 'Other') %>%
group_by(Country) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_Country, 10)
xname <- 'Country'
yname <- 'Count'
fun1(data, reorder(data$Country, data$Count), data$Count, xname, yname)
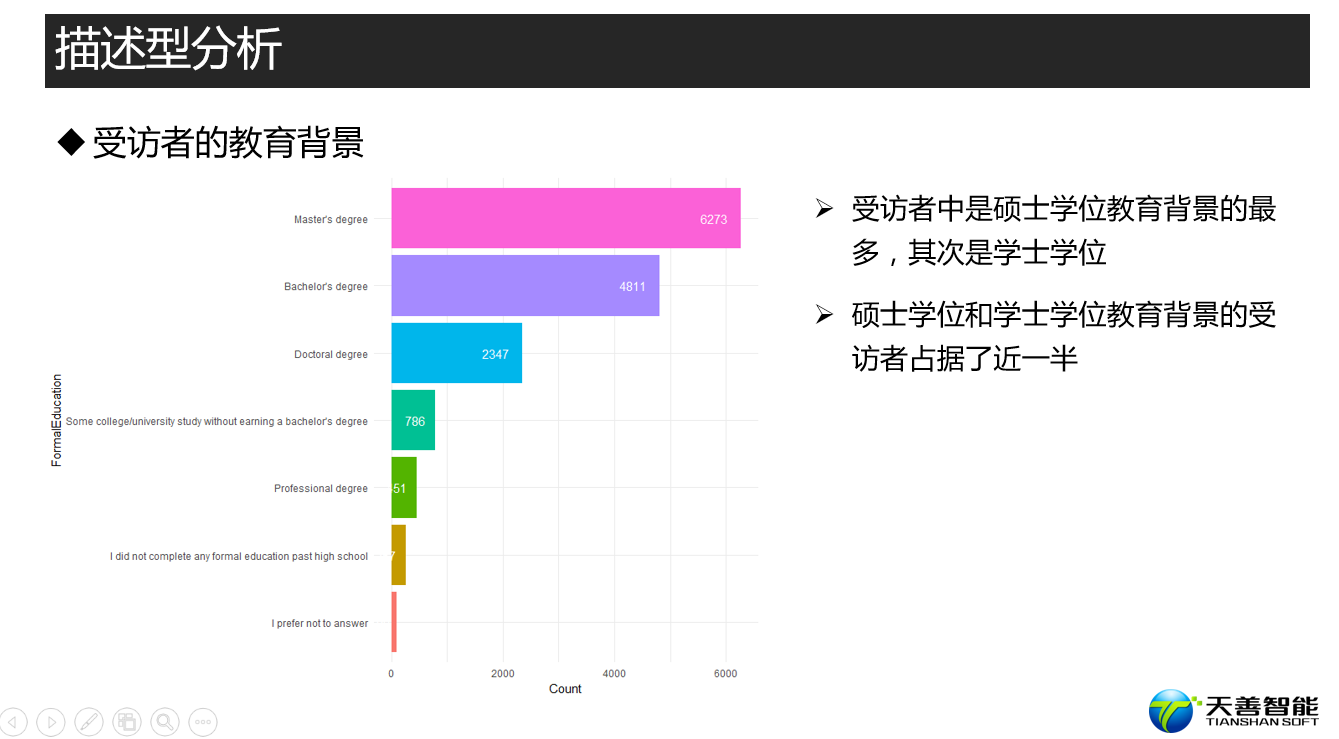
################# =========== 受访者的学历水平 ===================== ###########
## 探索kaggler的学历水平
# 创建绘图所需数据源(按照FormalEducation统计其个数,比按照其个数降序排列)
df_Education <- responses %>%
filter(FormalEducation != '') %>%
group_by(FormalEducation) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_Education, 10)
xname <- 'FormalEducation'
yname <- 'Count'
fun1(data, reorder(data$FormalEducation, data$Count), data$Count, xname, yname)
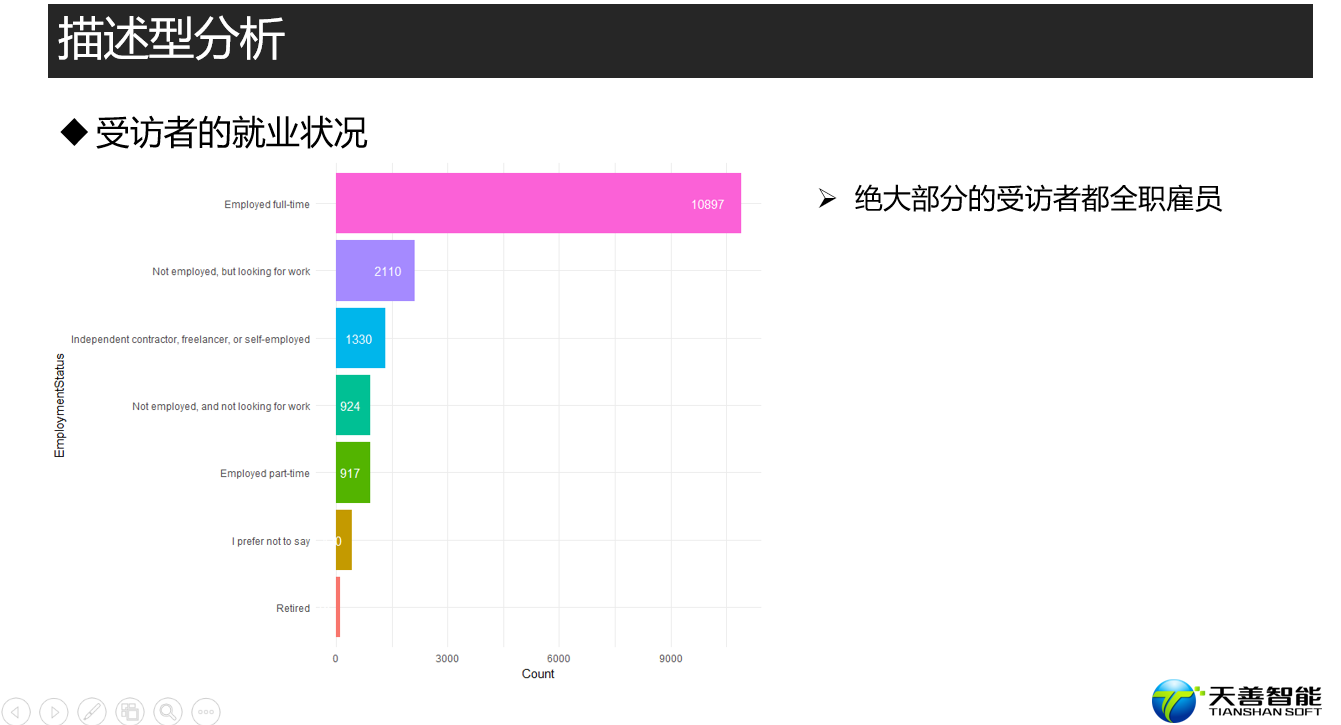
################# =========== 受访者的就业状况 ================ ################
## 探索kaggler的就业状况
# 创建绘图所需数据源(按照EmploymentStatus统计其个数,比按照其个数降序排列)
df_Employment <- responses %>%
group_by(EmploymentStatus) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- head(df_Employment, 10)
xname <- 'EmploymentStatus'
yname <- 'Count'
fun1(data, reorder(data$EmploymentStatus, data$Count), data$Count, xname, yname)
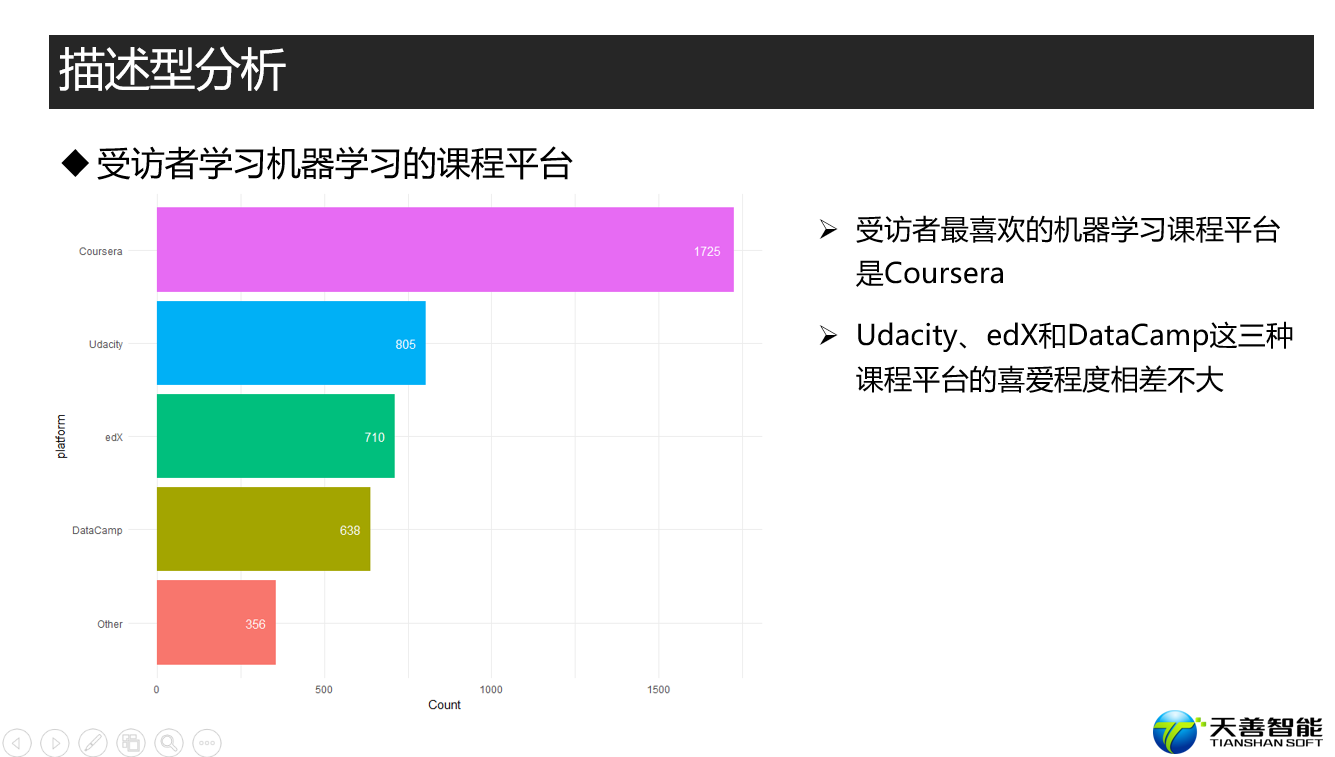
################# =========== 受访者的学习平台 =============== #################
## 探索kaggler在什么平台学习数据科学
# 按照‘,’拆分字符串---把CoursePlatformSelect列的字符依据‘,’拆分
platform <- unlist(strsplit(responses$CoursePlatformSelect, ','))
# 统计不同字符串(平台)的频次并转换成数据框
platform <- as.data.frame(table(platform))
data <- platform
xname <- 'platform'
yname <- 'Count'
fun1(data, reorder(data$platform, data$Freq), data$Freq, xname, yname)
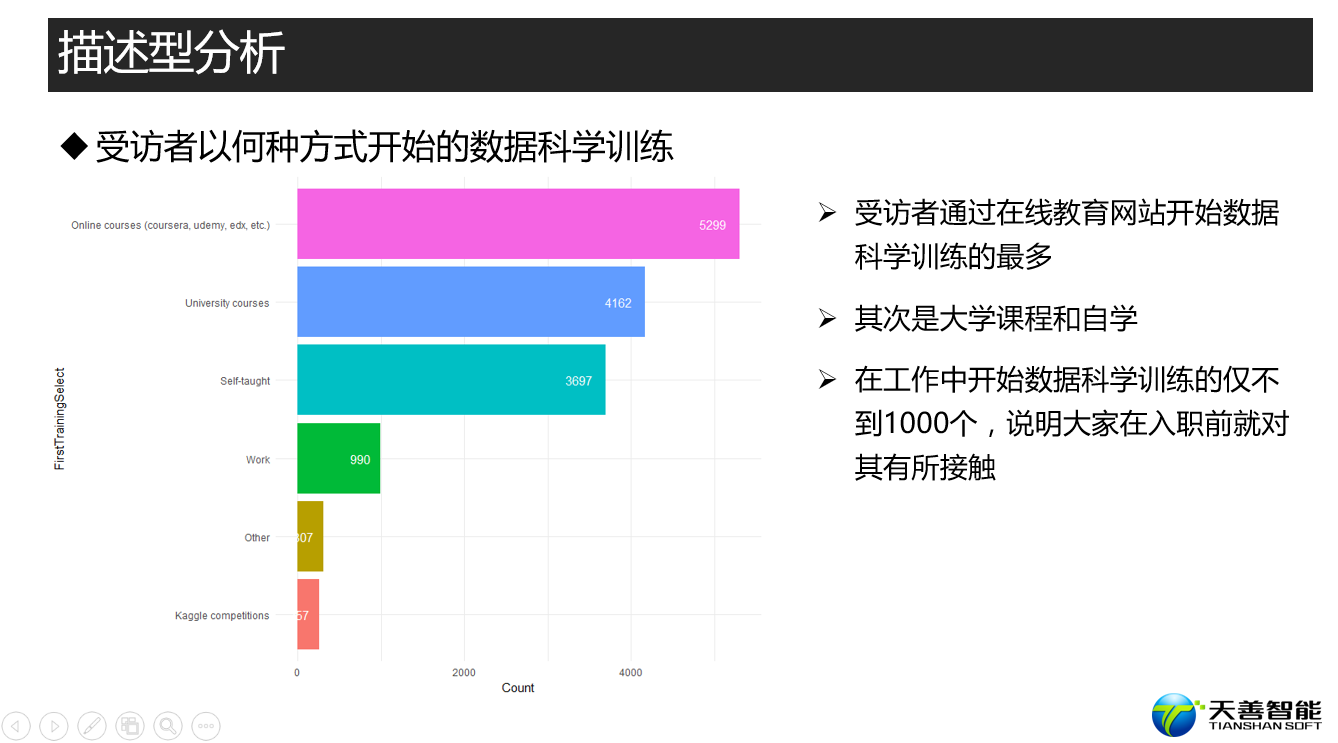
## 探索kaggler何种方式开始学习数据科学的
# 创建绘图所需数据源(按照FirstTrainingSelect统计其个数,比按照其个数降序排列
df_FT <- responses %>%
filter(FirstTrainingSelect != '') %>%
group_by(FirstTrainingSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- df_FT
xname <- 'FirstTrainingSelect'
yname <- 'Count'
fun1(data, reorder(data$FirstTrainingSelect, data$Count), data$Count, xname, yname)
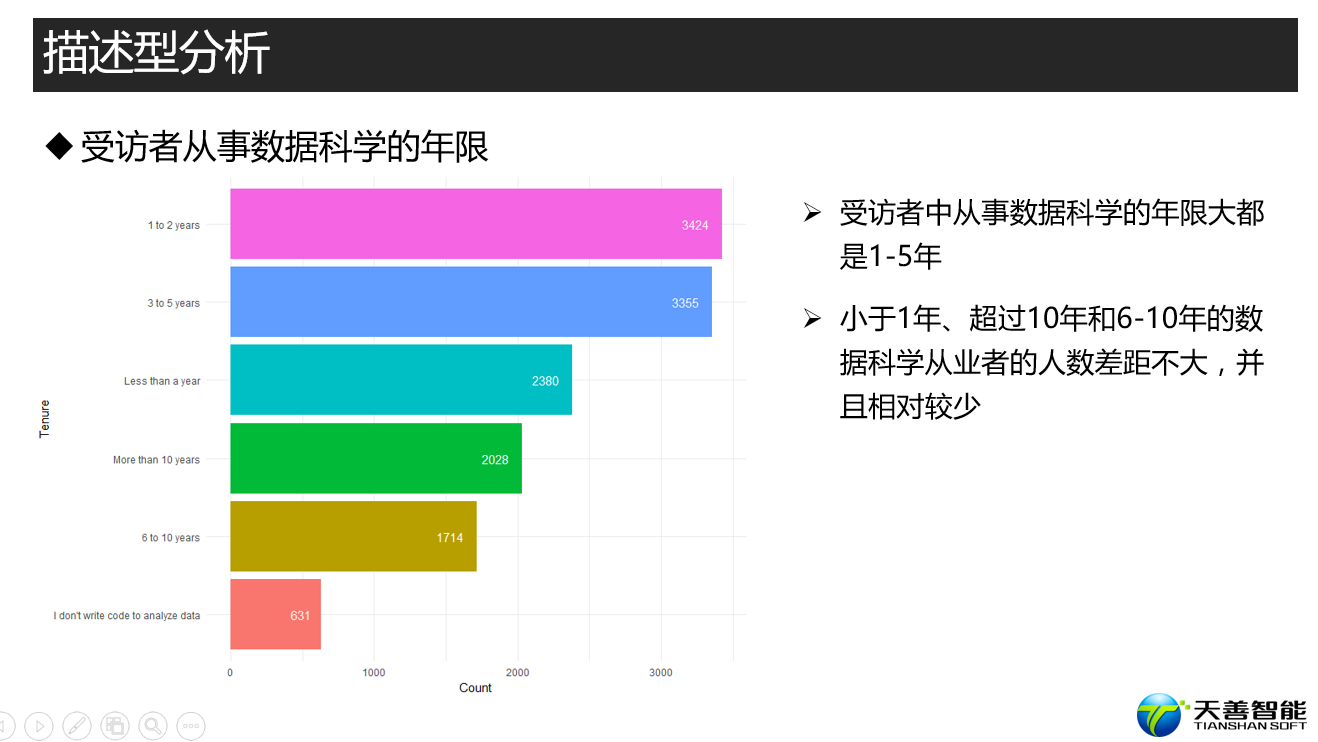
################# =========== 任职数据科学的时间 =============== ###############
## 探索kaggler任职数据科学的时间
# 创建绘图所需数据源(按照Tenure统计其个数,比按照其个数降序排列
df_Tenure <- responses %>%
filter(Tenure != '') %>%
group_by(Tenure) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- df_Tenure
xname <- 'Tenure'
yname <- 'Count'
fun1(data, reorder(data$Tenure, data$Count), data$Count, xname, yname)
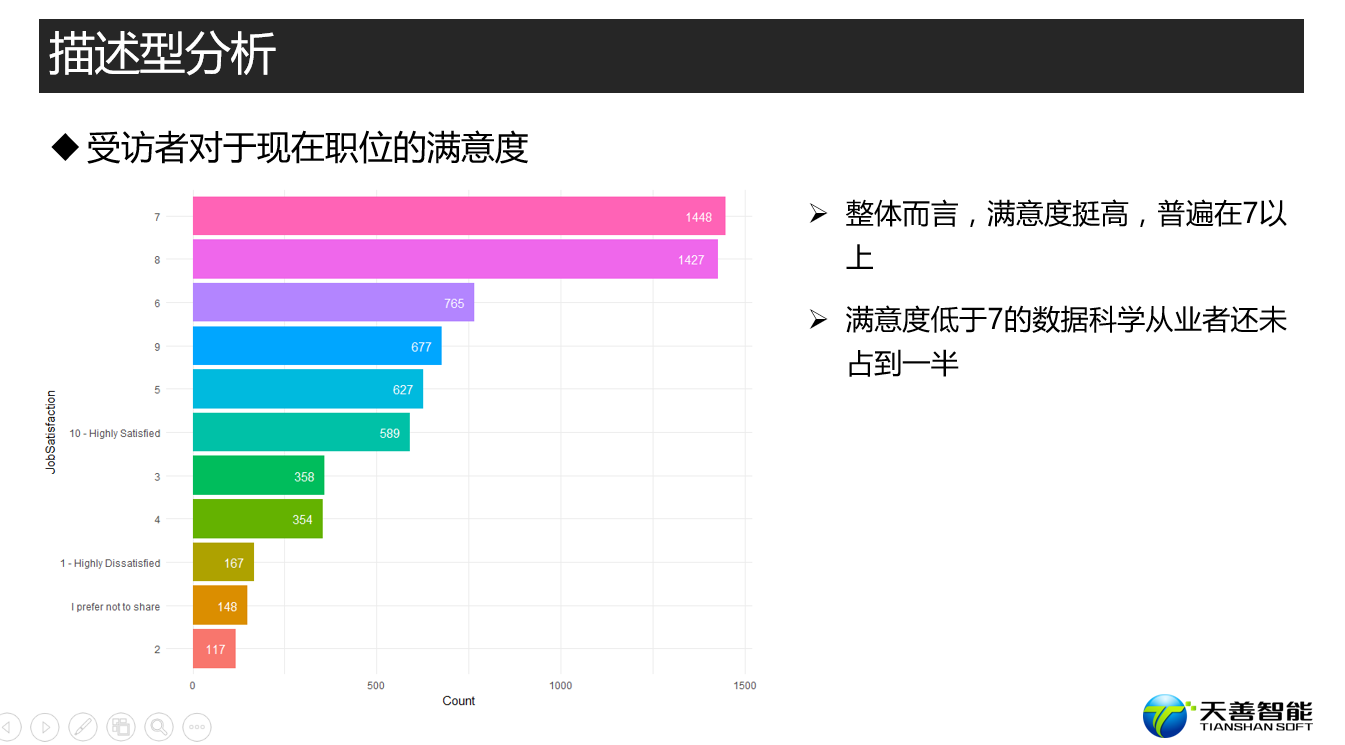
################# =========== 现任职的满意度 ======= ###########################
## 探索kaggler对现职位的满意度
# 创建绘图所需数据源(按照JobSatisfaction统计其个数,比按照其个数降序排列
df_JS <- responses %>%
filter(JobSatisfaction != '') %>%
group_by(JobSatisfaction) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- df_JS
xname <- 'JobSatisfaction'
yname <- 'Count'
fun1(data, reorder(data$JobSatisfaction, data$Count), data$Count, xname, yname)
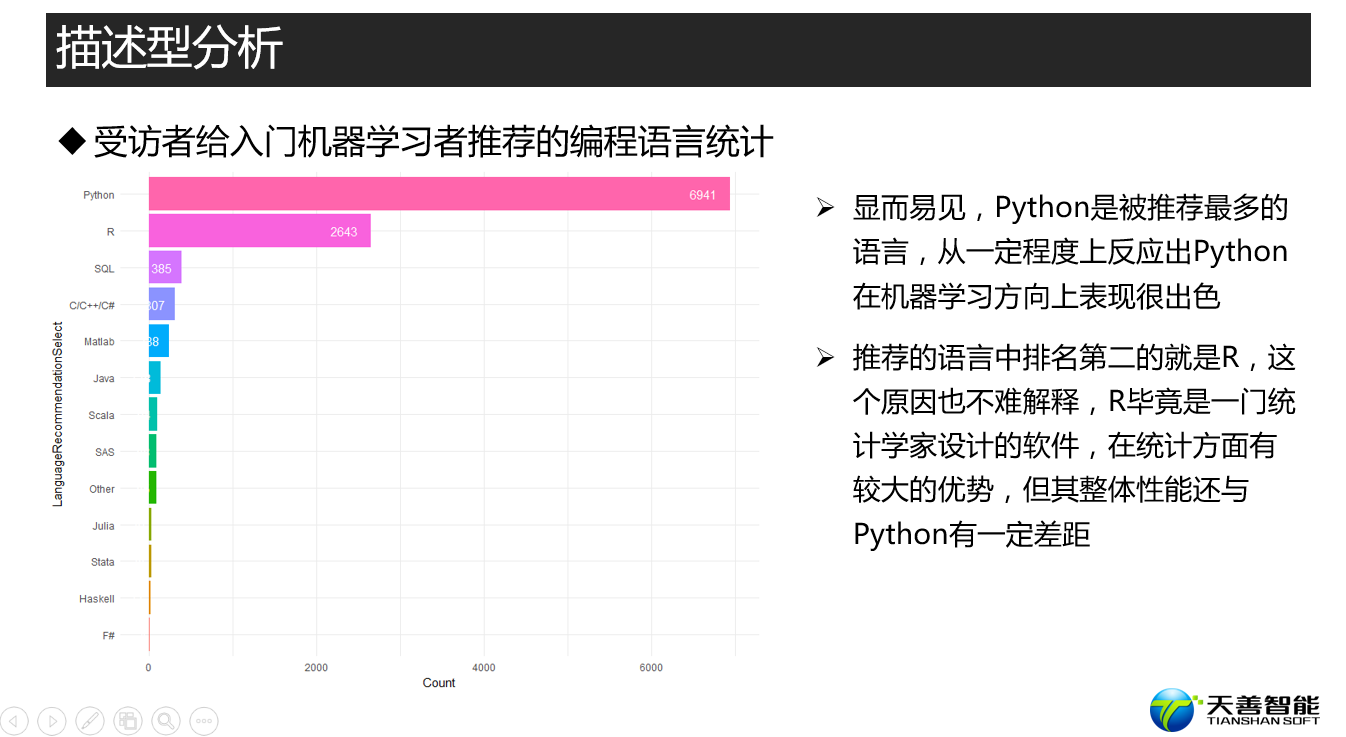
################# =========== 首推的数据科学语言 ========== ####################
## 探索kaggler的首选语言
# 创建绘图所需数据源(按照LanguageRecommendationSelect统计其个数,并按照其个数降序排列
df_LR <- responses %>%
filter(LanguageRecommendationSelect != '') %>%
group_by(LanguageRecommendationSelect) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
data <- df_LR
xname <- 'LanguageRecommendationSelect'
yname <- 'Count'
fun1(data, reorder(data$LanguageRecommendationSelect, data$Count), data$Count, xname, yname)
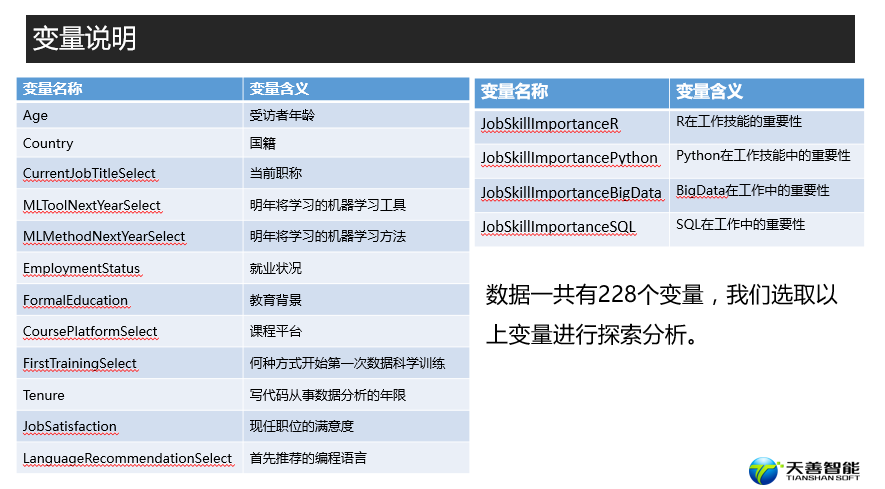
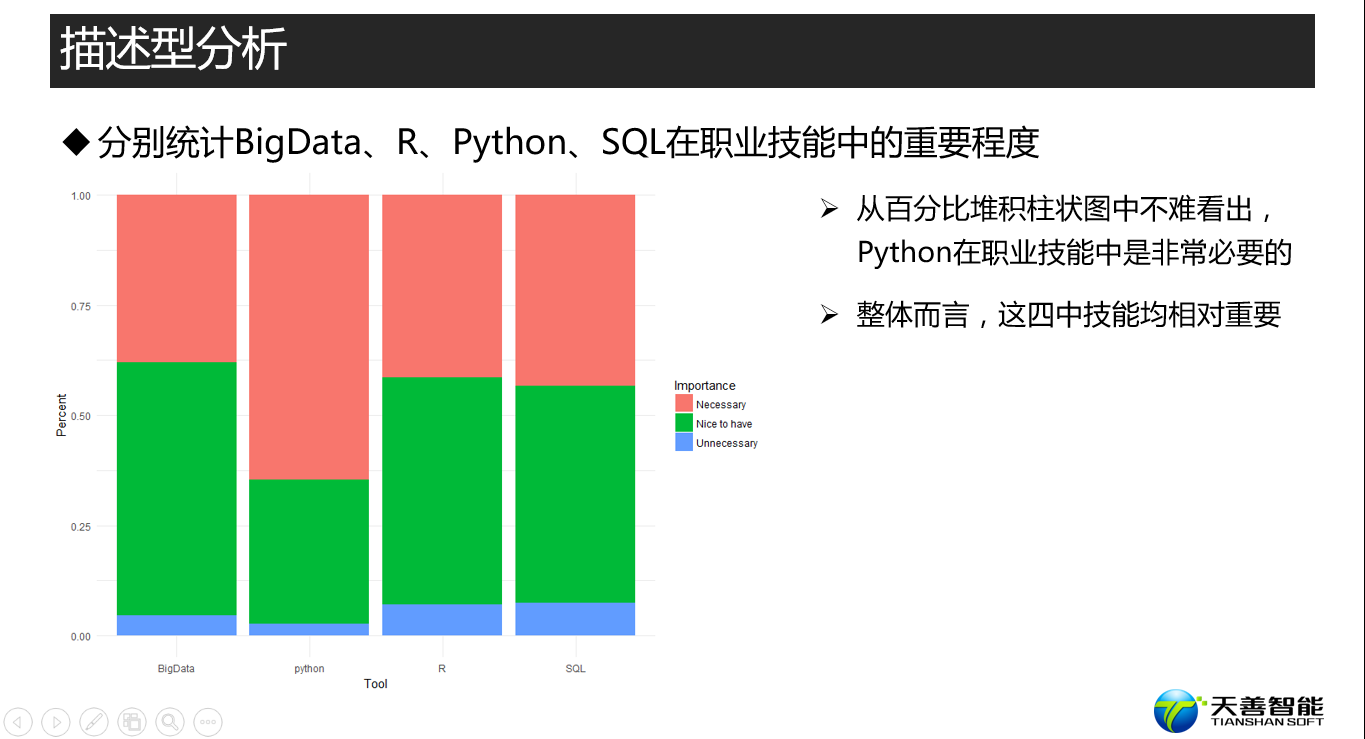
################# =========== BigData数据科学证书、R、Python、SQL的重要程度 ====== ##########
## 创建新数据框(按照JobSkillImportanceR统计其个数,并按照Count降序排列)
df_r <- responses %>%
filter(JobSkillImportanceR != '') %>%
group_by(JobSkillImportanceR) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
df_r$Tool <- 'R' # 创建新列,并赋值为‘R’
names(df_r) <- c("Importance", "Count", "Tool") # 对数据框重命名
df_python <- responses %>%
filter(JobSkillImportancePython != '') %>%
group_by(JobSkillImportancePython) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
df_python$Tool <- 'python'
names(df_python) = c("Importance", "Count", "Tool")
df_BigData <- responses %>%
filter(JobSkillImportanceBigData != '') %>%
group_by(JobSkillImportanceBigData) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
df_BigData$Tool <- 'BigData'
names(df_BigData) = c("Importance", "Count", "Tool")
df_SQL <- responses %>%
filter(JobSkillImportanceSQL != '') %>%
group_by(JobSkillImportanceSQL) %>%
summarise(Count = n()) %>%
arrange(desc(Count))
df_SQL$Tool <- 'SQL'
names(df_SQL) = c("Importance", "Count", "Tool")
df_end <- rbind(df_python, df_r, df_BigData, df_SQL) # 对四个数据框进行行合并
## 绘制百分比堆积柱状图
# position = 'fill'意味着绘制百分比堆积柱状图
ggplot(df_end, aes(x = Tool, y = Count, fill = Importance)) +
geom_bar(position = 'fill', stat = 'identity') +
labs(y = 'Percent') +
theme_minimal()
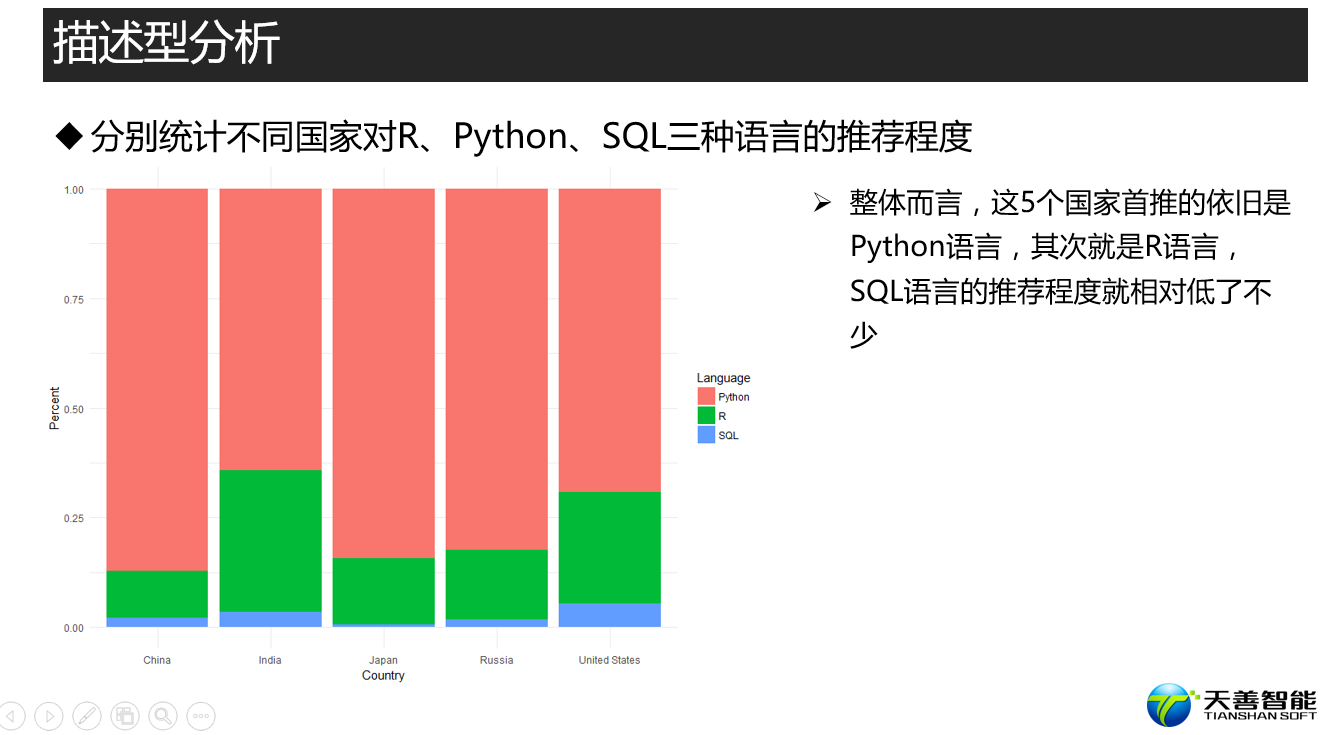
################# =========== 5个不同国家对SQL、R和Python的推荐 ======== #######
## 创建数据源(以下5个国家+以下3个语言的观测)
df_country_language <- responses[responses$Country %in%
c("United States", "India", "Russia", "Japan", "China") &
responses$LanguageRecommendationSelect %in% c("R", "Python", "SQL"), ]
# 创建绘图所需数据源(按照Country+LanguageRecommendationSelect的组合统计其个数
df_cl <- df_country_language %>%
group_by(Country, LanguageRecommendationSelect) %>%
summarise(Count = n())
# 绘制百分比堆积柱状图(5个国家首推3个语言对比)
ggplot(df_cl, aes(x = Country, y = Count, fill = LanguageRecommendationSelect)) +
geom_bar(stat = 'identity') +
labs(y = 'Percent') +
theme_minimal()