数据挖掘从开始到结束主要分为6个步骤:业务理解、数据搜集、数据整理、数据建模、模型评估以及模型部署。抛开将业务转化为模型的业务理解以及对建立好的模型的模型部署两部分,本文将对建模过程当中的核心4步骤:数据搜集、数据整理、数据建模、模型评估进行归纳和整理。每一部分,笔者都会从三个角度进行归纳:1.该部分到底是要做什么;2.该部分常用的R实现;3.该部分常用的python实现。
下面就让我们进入正题吧——gogogo!
一.数据采集
当将业务问题转化成建模目标之后,第一步要做的便是根据业务采集本次建模所需要的所有数据。将数据采集好之后,我们需要将其导入数据分析软件中,以便于接下来的建模使用。
1.1R实现
建模最开始,需要设置路径,以方便后续导入导出以及保存等流程。在R中,设置路径方式如下。
#查看工作路径
getwd()
#设置工作路径
setwd('G:/test/')
在R中,笔者最常用的数据导入方式有三种。
1.1.2csv导入
导入csv文件,有两种常用写法。
#法1
data<-read.csv('filename.csv',seq=',',header=TRUE)
#法2
data<-read.table('filename.csv')
1.1.3excel导入
导入excel文件,在R中有两个惯常使用的包——xlsx和XLConnect。
#法1
library(xlsx)
workbook<-"/data.xlsx"
data<-readxlsx(workbook,1)
#法2
library(XLConnect)
wb<-loadWorkbook("data.xlsx")
data<-readWorksheet(wb,sheet=getSheets(wb)[1])
1.1.4数据库导入
导入数据库数据,通常使用ROCBC包。
library(RODBC)
#连接数据库
channel<-odbcConnect("数据库名",uid="用户名",pwd="密码",believeNRows=FALSE)
#读取数据的sql
data<-sqlQuery(channel,"select * from data")
1.2python实现
1.2.1路径设置
import os
#查看工作路径
os.getcwd()
#设置工作路径
os.chdir("G:\\test\\")
1.2.2csv导入
import pandas as pd
data = pd.read_csv("filename.csv")
1.2.3数据库导入
因为笔者用的是oracle数据库,所以这里以oracle数据库为例。
import cx_Oracle as co
#创建连接
db = co.connect('用户名/密码@ip:1521/服务名')
#创建cursor
cursor = db.cursor()
#用sql写出想要的数据
sqldata='select * from data'
#执行sql语句
cursor.execute(sqldata)
#用完之后关闭数据库
db.close()
二.数据处理
导入数据之后,第二步需要做的是对数据进行处理,使得数据达到建模对数据的要求。
数据处理主要分为如下的几个步骤:数据探索、缺失值处理、异常值处理、数据格式转换、数据标准化。
2.1数据探索
数据处理的第一步,通常使用描述性统计去探索数据量、字段类型等基本信息。
#R实现
#查看数据结构
class(data)
str(data)
#最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计
summary(data)
#python实现
#查看数据结构
data.shape
data.dtypes
#最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计
data.describe()
查看数据信息,如果不同字段均值差异很大或者模型有需要,就要考虑数据标准化;如果某些字段类型不符合建模需要,就要对字段类型进行转换。
2.2缺失值处理
很多模型是要求数据当中不能存在缺失值的,因此,我们要检查数据当中是否存在缺失值,如果存在,需要对缺失值进行一定的处理。
2.2.1判断缺失值是否存在
table(is.na(data))
library(mice)
md.pattern(data)
library(VIM)
aggr(data,prop=FALSE,numbers=TRUE)
isnull = pd.isnull(data)
isnull_count = len(data[isnull.values==True])
判断之后,如果没有缺失值皆大欢喜,如果有缺失值,需要对缺失值进行插补或者是删除。
2.2.2删除缺失值
#r
data=data[complete.cases(data),]
data=na.omit(data)
data = data[isnull.values==False]
插补缺失值太过细化,这里暂不展开赘诉。
2.3异常值处理
2.3.1判断是否存在异常值
可用箱线图来判断数据是否存在异常值。
2.4数据格式转换
数据探索之后,如果发现有字段数据格式不符合建模要求,需要对格式进行转换。
data$x1<-as.numeric(data$x1)
data$x2<-as.character(data$x2)
data['x1'] =data['x1'].astype('Int32')
data['x2'] = data['x2'].astype('str')
2.5数据标准化
如果不同字段均值差异很大或者模型有需要,为了统一量纲,减小量纲给模型带来的误差,需要对数据进行标准化。
data_scale<-scale(data,center=T,scale=T)
library(caret)
data_center<-preProcess(data,method=c("center"))
data_range<-preProcess(data,method = c("range"))
import numpy as np
data = data.apply(lambda x:(x-np.mean(x)/np.std(data)))
data = data.apply(lambda x:(x-np.mean(x)))
data = data.apply(lambda x:(x-np.min(x))/(np.max(x)-np.min(x)))
三.数据建模
当数据整理成建模需要的格式之后,就进入数据挖掘最重要也是最核心的一步:数据建模。
在数据挖掘中,常用的数据挖掘算法分为预测、分类、聚类、关联规则、时间序列以及文本挖掘六个大类。下面,我将会归纳每个类常用的常用的几个算法,每个算法我将会简单地拎一拎它的理论核心以及在R或python中运用算法会用到的包。
在讲算法之前,还需要先提一个知识点,那就是数据分区。
3.1数据分区
在机器学习中,一般将建模的数据样本data分为训练集train和测试集test,使用训练集估计模型,使用测试集评估模型优劣。
library(caret)
index<-createDataPartition(y,times=1,p=0.75)
train<-data[index,]
test<-data[-index,]
from sklearn.cross_validation import train_test_split
x=data.iloc[:,1:(n-1)].values
y=data.iloc[:,n].values
(x_train,x_test,y_train,y_test)=train_test_split(x,y,train_size=0.75,random_state=1234)
除了将数据简单地分为训练集和测试集之外,还可以进行k折交叉验证,这不是本文的重点,在此不进行展开。
3.2预测
预测模型指的是建立模型对连续函数值型的目标函数进行估计预测。属于预测的模型中,常见的有线性回归,岭回归,lasso回归,回归树,SVM,神经网络,下面,我将会对它们一一进行概要总结。
3.2.1线性回归
线性回归,即是对Y=∑βX做最小二乘法(OLS)估计,求解参数β,从而得出模型。
lr_fit<-lm(x,y,data=train)
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr_fit=lr.fit(x_train,y_train)
3.2.2岭回归
偏差描述了训练集在样本上的拟合程度,方差描述了模型的移植性,即用测试集验证模型模型的优度。方差和偏差需要同时小模型才好,如果偏差大,模型本身的优度糟糕,但如果一味地追求偏差使得方差大,那么即使在训练样本上拟合再好,一换了测试集就GG的这种可移植性差的模型也是没有意义的。
随着模型复杂度增加,方差和偏差会经历先同高,后同低,最后过拟合,方差高偏差低的过程。
岭回归是在线性回归的基础上给线性回归实际值减去估计值得到的平方误差((Y−XW)2)加上了一个正则项λ∑ω2j.通过正则项,可以使偏差和方差达到平衡。加上正则项,可以确定λ是的方差和偏差达到平衡。
library(MASS)
ridge_fit<-lm.ridge(y~.,lambda =0.1,data=train)
from sklearn import linear_model
ridge = linear_model.Ridge(alpha=0.1)
ridge_fit = ridge.fit(x_train,y_train)
3.2.3lasso回归
类似于岭回归,只不过lasso回归的惩罚项是绝对值λ||ω||1而不是平方。这导致惩罚值使一些参数估计结果为0,将会从给定的n个变量中选择变量。
因此,lasso不光可以用于预测,也可以用于选择合适的自变量。
library(glmnet)
lasso_fit <- glmnet(x, y, family="gaussian", nlambda=50, alpha=0.1)
from sklearn import linear_model
lasso =linear_model.Lasso(alpha=0.1)
lasso_fit = lasso.fit(x_train,y_train)
除此之外,ridge和lasso也可以做分类,将惩罚项与线性回归结合就是上面讲的预测问题,将惩罚项与logistics回归结合则是分类问题。因为ridge和lasso在线性回归中更有名,所以将其放在预测这一节讲。
同样的,决策树、SVM和神经网络都是既可以做分类又可以做回归。因为决策树、SVM和神经网络在分类中更有名,则将这三个算法放到下一节分类问题中进行整理。
3.3分类
分类模型指的是建立模型对离散型的目标函数进行分类标号。属于分类的模型中,常见的模型有logistics回归、决策树、SVM、神经网络、随机森林、还有最近比较火的GBDT。
3.3.1logistics回归
不同于线性回归,因为logistics回归的因变量是离散变量,因此需要对使用事件发生比ln(p1−p)将因变量转化为连续变量,然后与自变量进行线性回归,从而得到估计参数。
log_fit <- glm(y~.,family=binomial(link-'logit'),data=data)
import sklearn.linear_model import LogisticRegression
log = LogisticRegression()
log_fit = log.fit(x_train,y_train)
3.3.2决策树
决策树通过一个树结构,不断地对模型数据中的各个特征进行分类,最终到子节点得到输出因变量的一个类别。为了让模型尽可能地准确,需要从根节点对特征输入的先后顺序进行筛选。
筛选特征顺序,常见的有两种方式,一个是使用信息增益(率)进行筛选,代表算法是ID3和C4.5;另一种是使用gini指标进行筛选,代表算法是cart。
先讲信息增益。
信息增益使用熵(H=−pi∑log2pi)来定义的。信息增益gain=Entropy(s)−Entropy(s|t),其中s代表目标,s|t代表在特征t前提下的目标。选择信息增益最大的作为根节点,第二大的作为第二个节点,以此类推,这就是ID3算法。
因为信息增益有一个缺点是会偏向于选择特征多的节点,为了优化,出现了用信息增益率衡量的C4.5算法。信息增益率即gainrate=Entropy(s)−Entropy(s|t)Entropy(s),消除了特征数量带来的偏差。
再讲gini指标。
当cart计算分类时,每一个类别gini=1−∑p2i,gini值越小,节点值越纯,分类效果越好。对于一棵树的因变量特征,GINI=∑pi∗ginii.
当cart计算回归时,每一个类别的σ=∑(x−μ)2−−−−−−−−−√,对于一棵树的因变量特征,GINI=∑pi∗σi.
cart既可以计算分类树又可以计算回归树,但是只能是二叉树;ID3和C4.5既可以计算多叉树又可以计算二叉树,但是它只可以计算分类树。
library(rpart)
cart_model<-rpart(y~.,data=train)
library(C50)
c50_model<-C5.0(y~.,data=train)
#python
from sklearn import tree
tree=tree.DecisionTreeClassifier(criterion='entropy')
tree_model=tree.fit(x_train,y_train)
3.3.3决策树拓展——bagging和boosting
因为一颗决策树的预测容易不够准确,随着决策树发展,其开始出现了两个分支。
第一个分支是bagging类算法,其中最具代表性的就是随机森林。
3.3.3.1随机森林
随机森林对数据设定一个比例进行有放回的抽样,对特征设定一个比例无放回抽取,建立多个决策子树,最终的分类结果按照分类树集合在一起投票的多少而决定。
因为bagging算法的实质是先减小方差后减小偏差,因此树有可能比较深。
library(randomForest)
random_model<-randomForest(y~.,data=train,importance=TRUE,proximity=TRUE)
from sklearn.ensemble import RandomForestClassifier
random = RandomForestClassifier()
random_model = random.fit(x_train,y_train)
3.3.2GBDT
决策树的另一个分支是boosting算法,其中最具代表性的算法是GBDT。
不同于bagging,GBDT是串行算法,他是以cart回归树为基学习器,由原始数据建立第一棵树,然后利用得到的残差建立第二颗数,不断地迭代直到残差小于一定程度。
因为boosting算法的实质是先减小偏差再减小方差,所以树的深度一般比较浅。
library(gbm)
gbdt_model <-gbm(y~.,data=train)
from sklearn.ensemble import GradientBoostingDecisionClassifier
loss='deviance',
learning_rate=0.01,
n_estimators=50,
subsample=0.8,
max_features=1,
max_depth=3,
verbose=2)
gbdt_model = gbdt.fit(x_train,y_train)
3.3.4SVM
支持向量机(SVM)的核心思想是通过核函数,将低维线性不可分的函数抽象到高维,寻找一组支持向量,使得超平面切割的分类能够满足支持向量到超平面的距离最远。
library(e1071)
svm_model<-svm(y~.,data=train,kernel = 'radial')
from sklearn.svm import SVC
svm = SVC(kernel = 'rbf')
svm_model = svm.fit(x_train,y_train)
3.3.5神经网络
神经网络即将自变量输入进多层神经元中,得到输出。
library(nnet)
nnet_model<-nnet(y~.,data=train)
from sklearn.neural_network import MLPClassifier
nnet = MLPClassifier(hidden_layer_sizes=(20,20,20),activation='logistic',max_iter=100)
nnet_model = nnet.fit(x_train,y_train)
3.4聚类
不同于预测和分类都属于有监督学习,聚类和降维都属于无监督学习。因为降维通常用于梳理整理过程对指标进行降维处理,在此不展开讲述。
聚类的核心就是‘物以类聚,人以群分’,它并没有目标函数,而是根据指标系将样本或变量性质相似的分为一类。
常用的聚类算法有k-means聚类,层次聚类以及密度聚类。
3.4.1K-Means聚类
k-means聚类是基于划分的聚类。预先设定聚类个数,初始随机选择类中心,计算每个样本和类中心的距离,将样本归为最近的那个类中心确定的类中,分好类之后,计算每个类的类中心。重复上诉过程,直到类中心不再发生变化,聚类完成。
最常用的距离公式是欧几里得距离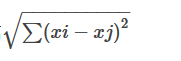
#R实现
library(stats)
kmeans_model<-kmeans(x,3)
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2,random_state=123)
y_kmeans = kmeans.fit_predict(x)
3.4.2层次聚类
层次聚类不需要事先设定类树K,可以通过类似于谱系图的方式从上到下或者从下到上计算出聚类结果。你可以根据需要,选择适合自己的聚类个数方法。
以从下到上为例。初始将每个样本归为一类,计算不同样本之间的距离,将最近的两个类合为一类,不断地合并直到最终只有一类。
层次聚类的缺点是速度慢
h<-hclust(dist)
from sklearn.clusters import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters=2,affinity = 'euclidean',linkage='ward')
3.4.3密度聚类
k-means算法有一个缺点是只适用于圆形的类别,当类别是其他形状,就最好考虑密度聚类。
随机选择一个样本点为核心对象,设定最小半径以及类中最小数据量,在半径内的点属于该样本点的类,在半径上的点为边界点,如果两个边界点互相在对方类中,则两类合并,当考察完所有点最终得出聚类结果。
密度聚类比较适用于选择噪声值。如果一个点既不是核心对象又不属于样本,则是噪声点。
library(fpc)
dbscan<-dbscan(x,eps=1,MinPts=4)
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=1,min_samples=4)
y_dbscan = dbscan.fit_predict(x)
4.模型评估
建好模型之后,就进入数据挖掘核心流程的最后一步,也就是模型评估。针对预测、分类、聚类算法,分别有不同的模型评估方式。
4.1预测算法评估
对于预测算法,通常采用计算实际值和估计值的误差或者误差率的方式,评估模型优劣。误差(率)越低,模型越优。
常用的误差有均方误差(MSE),绝对误差(MAE)。
4.2分类算法评估
对于分类算法,通常采用混淆矩阵、准确率和ROC曲线进行评估。准确率越高,ROC曲线越靠近左上角,模型越优。
#R实现
y_predict<-predict(model)
#混淆矩阵
t=table(y_test,y_predict)
混淆矩阵比例
prop.table(t)
#ROC曲线
library(ROCR)
pred <- prediction(y_predict,y_test)
performance(pred,'auc')#y.values #AUC值
perf <-[erfpr,amce)pred,'tpr','fpr')
plot(perf)
import pandas as pd
t=pd.crosstab(y_test,y_predict,rownames=["Actual"],colnames=["Predicted"])
from sklearn.metrices import roc_curve,auc
import matplotlib.pyplot as plt
proba_=model.predict_proba(x_test)
fpr,tpr,thresholds=roc_curve(y_test,proba_[:,1])
plt.plot(fpr,tpr,label="ROC curve")
plt.plot([0,1],[0,1],'k--')
plt.xlim([0.0,1.0])
plt.ylim([0.0,1.0])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.legend('lower right')
plt.show()
auc=auc(fpr,tpr)
4.3聚类算法评估
聚类算法通常选用轮廓系数评估模型优劣程度,它可以评估不同聚类算法的优劣程度,选出最合适的聚类模型;也可以评估一个聚类算法不同类个数的优劣程度,选出最合适的聚类个数。
轮廓系数结合内聚度a(i)和分离度b(i)两种因素
轮廓系数的值在-1到1之间,值越大表示聚类效果越好。
library(fpc)
cluster.stats(dist(data),result$cluster)
from sklearn import metrics
silhouette_score(X,y_pre)
以上,就是我对数据挖掘流程简单的整理。


