周末两天的培训结束了,非常感谢这段时间老师的热情指导,现对起点小说排名信息的爬取已完成,具体思路如下:
第一步:首先选取起点的网站网址:https://www.qidian.com/rank/hotsales,先尝试用代理和cookies进入网址,发现得到的界面源代码都没有问题,然后去掉代理和cookies发现也能爬取信息
使用代理和headers运行程序:
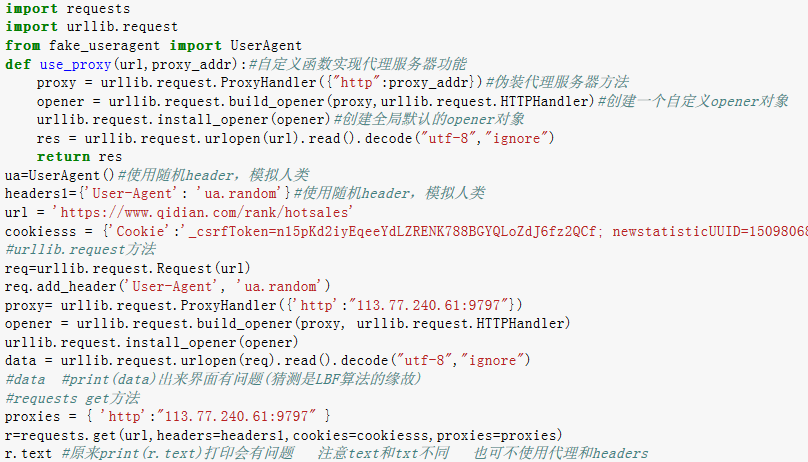
不使用代理运行程序结果:
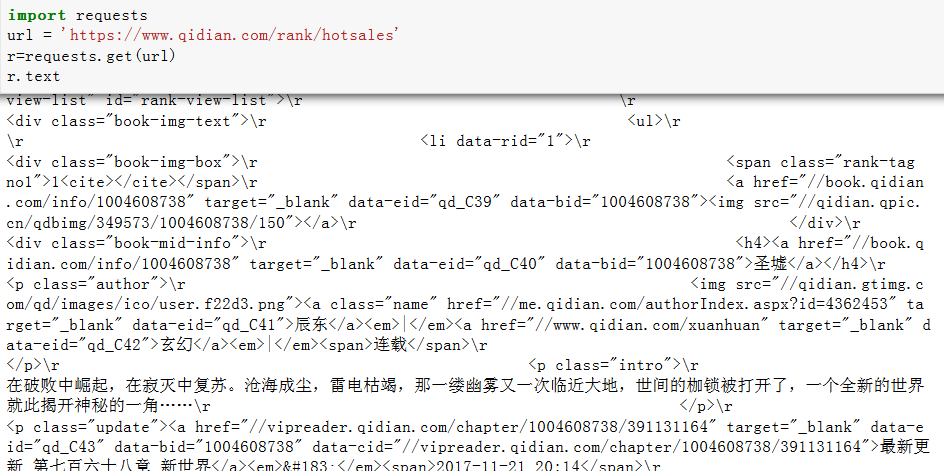
第二步:查看起点排行榜多个界面,发现只是后面的page=不同,取出所有的源代码信息,发现所有内容都在class=book-mid-info的a标签上,然后用BS4来对整个网页内容的提取,使用find_all和css的select方法都可以得到结果,结果如下:
find_all方法:
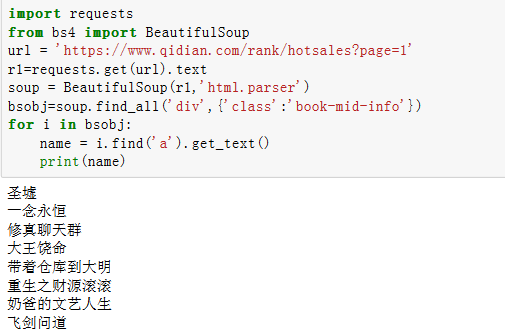
select方法:
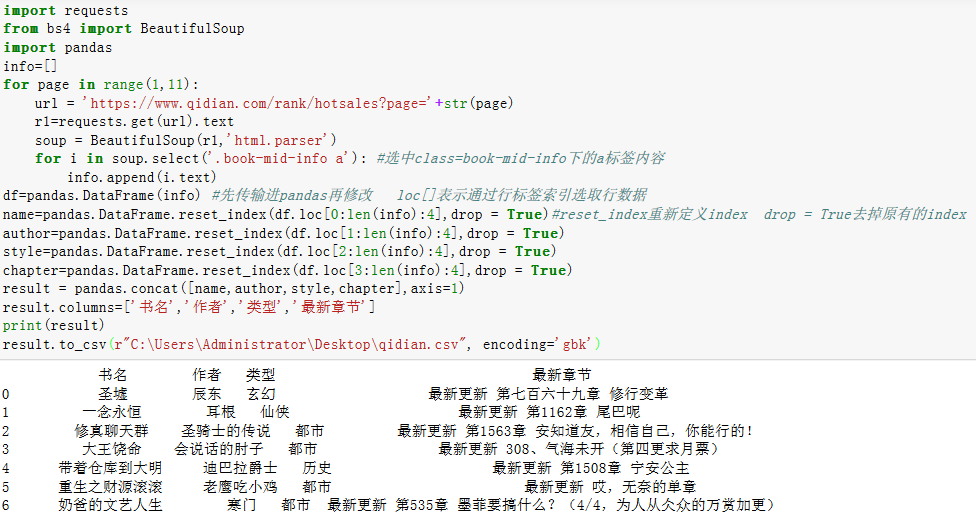
第三步:在这里使用css的select方法提取数据,然后把数据转变为pandas的DataFrame格式,因为数据都是在同一列,需要对数据进行切片及去掉原有索引,然后用pandas的concat把书名、作者等信息进行合并
数据传入DataFrame结果:

用pandas的concat把作者等信息进行合并运行后的结果:

最后就是保存在csv中,因为格式不同,需要对数据使用gbk格式写入
下图即是所有的代码: