
总第82篇
01|概念及原理:
EM算法是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计,或极大后验概率估计。EM算法的每次迭代分两步完成:E步,求期望(expectation);M步,求极大值(maximization).所以这一算法称为期望极大算法,简称EM算法。(你看懂了吗?反正我第一次看是一脸懵。没关系接下来通过一个例子,你就能明白了。)
(三硬币模型) 假设有A,B,C这些硬币正面出现的概率分别是π,p和q。进行如下掷硬币试验:先掷硬币A,根据其结果选出硬币B或C,正面选硬币B,反面选硬币C;然后掷选出的硬币,掷硬币的结果出现正面记作1,出现反面记作0;独立重复n次试验(这里n=10),观测结果如下:1,1,0,1,0,0,1,0,1,1
假设只能看到掷硬币的结果,不能观测掷硬币的过程,问如何估计三硬币正面出现的概率,即三硬币的模型参数(即π,p和q),求解这个模型参数的过程就是EM算法,也可以说是EM算法的目的就是求取这个模型的最大化参数。(硬币A出现的结果就是隐变量)
下图中红色问号就是一个隐变量,在整个过程中我们是看不到A的结果,我们只能看到最后红色1的结果,而我们现在要做的就是通过红色1的结果去求取A、B、C正面出现的概率。求取的原则是使A、B、C的概率最大化,求取的方法是不停迭代(也就是不停地试),直到概率最大为止。
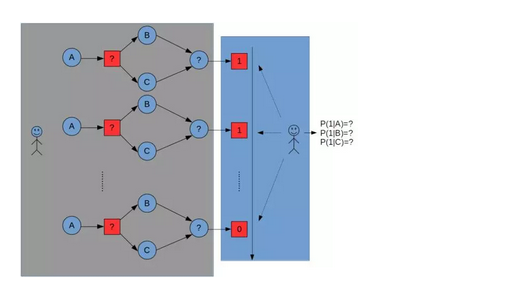
本图来源于:http://blog.csdn.net/sajiahan/article/details/53106642
02|数学推导:
一般地,用Y表示观测随机变量的数据,Z表示隐随机变量的数据。Y和Z在一起称为完全数据,观测数据Y又称为不完全数据。假设给定观测数据Y,其概率分布是P(Y|θ),其中θ是需要估计的模型参数,那么不完全数据Y的似然函数是P(Y|θ),对数似然函数L(θ)=logP(Y|θ);假设Y和Z的联合概率分布是P(Y,Z|θ),那么完全数据的对数似然函数是logP(Y,Z|θ)。


03|算法步骤:
EM算法就是通过迭代求L(θ)=logP(Y|θ)的极大似然估计。

EM算法步骤的第一步就是设定一个参数初值,这是人为设定的,这个值将会影响后续的参数迭代。
Q函数:
Q函数其实就是L(θ),也就是EM算法其实就是求取Q函数的极大值。

04|EM算法的应用:
EM算法常用在非监督学习问题中,即训练数据只有输入没有对应的输出。EM算法可以用于生成模型的非监督学习。生成模型由联合概率分布P(X,Y)表示,可以认为非监督学习训练数据是联合概率分布产生的数据。X为观测数据,Y为未观测数据。
