思路:
- 首先爬取整个页面源码,这个比较简单
- 保存到本地供测试用,省的每次测试都要爬取一遍
- 分析源码,使用beautifulSoup的find_all找出需要的tag即可。
代码:
# -*- coding:utf-8 -*-
import urllib.request
import re
from bs4 import BeautifulSoup
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
'''
url ='https://www.qiushibaike.com/hot/'
header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/59.0.3071.109 Safari/537.36'}
req = urllib.request.Request(url,headers = header)
res = urllib.request.urlopen(req)
data = res.read()
data = data.decode('utf-8')
with open(r"D:\python学习笔记\爬虫\保存记录\7_糗事百科HTML.txt",'w',encoding = 'utf-8') as f:
f.write(data)
'''
file = open(r"D:\python学习笔记\爬虫\保存记录\7_糗事百科HTML.txt",'r',encoding='utf-8')
data = file.read()
file.close()
#print(data)
soup = BeautifulSoup(data,'lxml')
#print(soup.find_all(class_="article block untagged mb15 typs_long"))
#分别获取内容和作者及点赞数等
content = []
for div in soup.find_all(name = 'div',class_ = 'content') :
content.append(div.text)
#print(div.text)
author = []
birth = []
for div in soup.find_all(name = 'div',class_='author clearfix'):
author.append(div.h2.text)
birth.append(div.div.text)
#print(author)
#print(birth)
#点赞数
agree = []
for span in soup.find_all(name = 'span',class_='stats-vote'):
agree.append(span.i.text)
#print(agree)
#评论数
comment = []
for a in soup.find_all(name = 'a',onclick = "_hmt.push(['_trackEvent','web-list-comment','chick'])"):
comment.append(a.i.text)
#print(comment)
#print(len(comment))
for i in range(len(author)) :
#print(author[i]+birth[i]+agree[i]+comment[i]+content[i])
#字符串换行需要在每行的末尾加\,或者用 ''' ''' 或者 """
str_n = '==============================第%s个笑话============================\n'%(i+1)
str1 = '作者:'+author[i].replace('\n','')+'\n'\
'年龄:'+ birth[i].replace('\n','')+'\t'\
'点赞:'+agree[i].replace('\n','')+'\t'\
'评论:'+comment[i].replace('\n','')+'\n'\
'内容:'+content[i].replace('\n','')+'\n'+'\n'
with open(r"D:\python学习笔记\爬虫\保存记录\7_03糗事百科HTML.txt",'a',encoding = 'utf-8') as f:
f.write(str_n + str1)
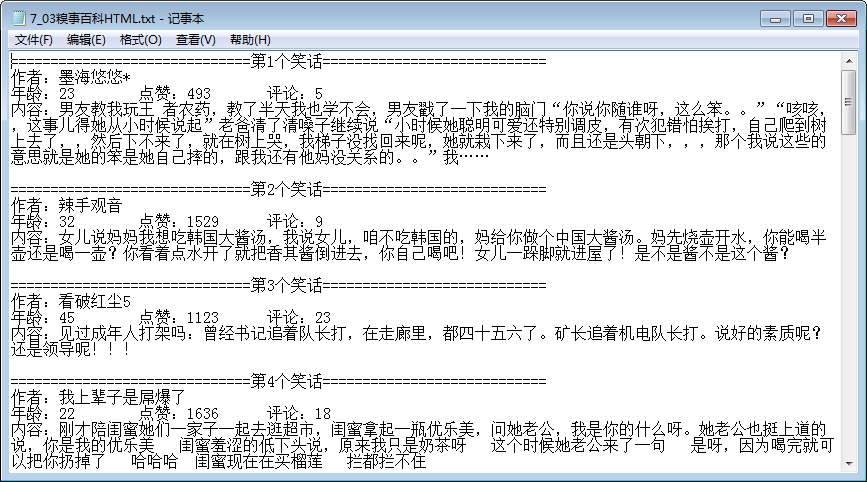
效果图:
总结:
因为刚开始学习使用BeautifulSoup,整体感觉比使用正则简单很多,代码量也少了,不用去匹配那么多东西!可能爬取的东西比较简单,希望大家多多交流,给予指正

