从业务应用的角度,我大致把数据挖掘的应用场景分为三大类:第一,个性化推荐与精准营销;第二,监督管理;第三,经营预测。不同行业侧重不同。
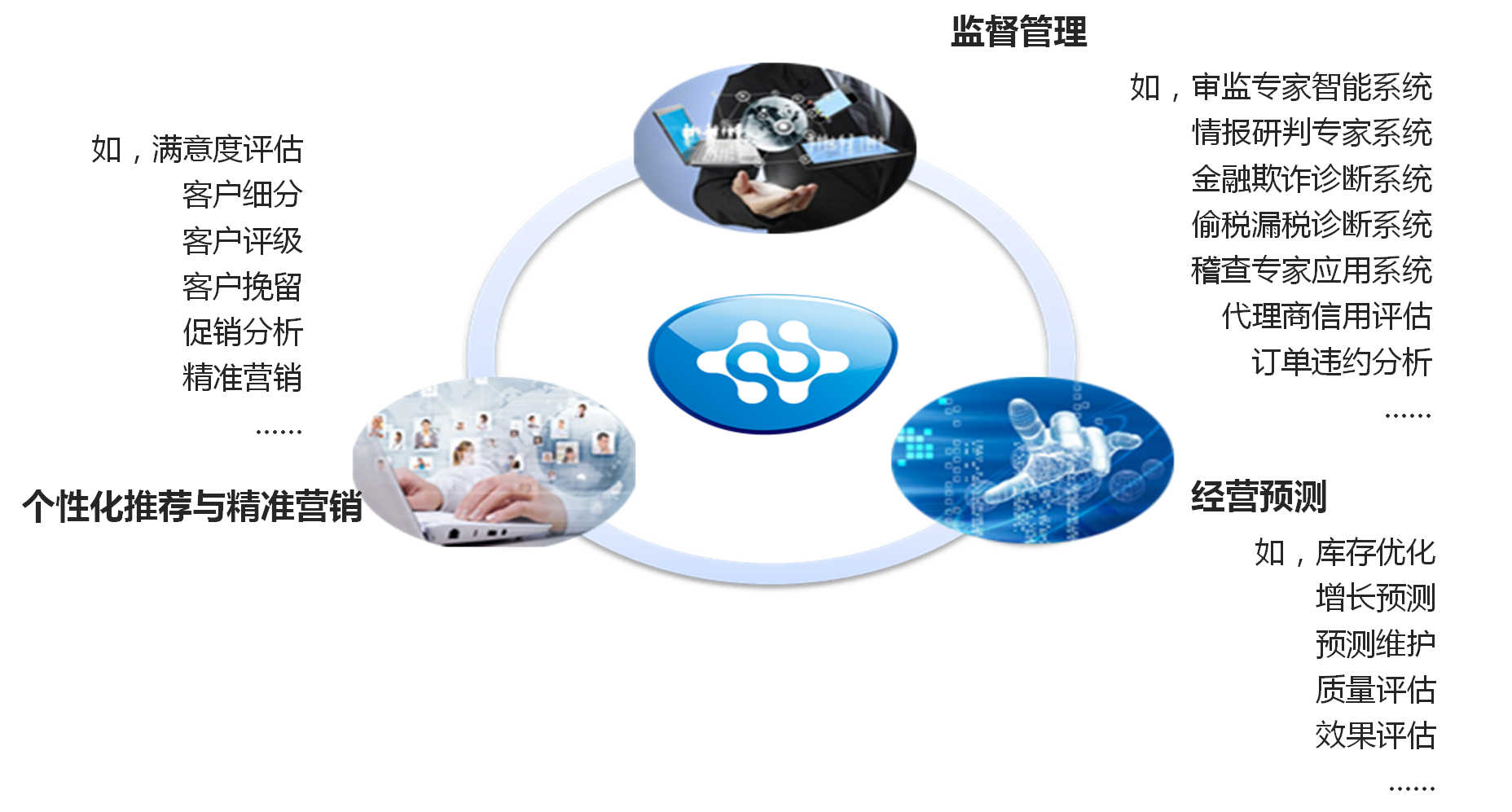
个性化推荐与精准营销:这类主要指精准推荐类场景。主要用于个性化推荐服务、广告推荐和精准营销等。所涉及的算法有聚类分析、分类预测、关联分析、社会网络分析等。
监督管理:这一类的应用场景比较特殊,多模型并行和混合应用。主要包括异常分析、违约分析和欺诈分析等。比如在检查一个设备是否有异常时,我们可以使用几百个模型来判断该设备是否有异常,只要有一个模型判断出来有异常,我们就可以判定为异常,越多的模型判断出异常则越异常,这些模型之间即独立又关联,而且后期可以不断加入新的模型。这次要分享的就属于这一类。所涉及的算法有聚类算法、偏差法、分类预测等。
经营预测:这类应用的特点是和日期相关,预测某个特征在未来各个时间上的表现情况。主要用于企业规划、预算体系和库存优化等。如预测某个产品未来每个月的销量、某些材料未来的需求量等。
下面重点聊一下第二类应用场景。咱们以三个小故事分别解释一下异常分析、违约分析和欺诈分析三种常见的监督管理应用。
第一个故事:农业补贴领用欺诈分析
这个案例之前已经在天善论坛写博客分享,大家可以好好看一看,这是一个经典的案例:http://ask.hellobi.com/blog/SmartMining/2378,附件中有详细的实现过程。
这个案例描述的是这样一个场景,政府对于农业有补贴,积累了农业补贴的领用数据,政府不知道这些领用是否合理或者存在欺诈,因此想通过数据挖掘的手段评估一下农户的领用金额是否存在异常。数据中记录了农户的姓名、所在区域、拥有田地的大小、降雨量、田地质量水平、田地收入、主要农作物、申请补贴的类型和申请补贴的金额。
业务目标:分析哪些农户领用补贴存在异常,并输出可疑的名单。
数据挖掘目标:建立异常检测模型,输出可疑名单。
通过这个案例我们探讨一下多模型异常诊断的问题。也重点掌握以下几点:
第一,如何结合业务理解,通过业务规则来进行异常分析,当然这是一个典型的以业务为驱动的数据挖掘项目。这一点也是大数据挖掘和传统数据挖掘相比要更加侧重的一点。因为大数据分析更要讲究生产力,所以数据价值的挖掘效率非常关键,否则我们的数据挖掘能力很难给企业带来实际的价值。要做到这一点,分析目标就要非常明确,就要以业务为驱动,面向某个业务问题聚焦一点进行挖掘,避免没有目标的乱挖。在这个案例中,通过统计农户的领用次数发现,除了两个农户之外,剩下的农户领用次数都只有一次,而这两个农户领用次数分别为2次和4次。我们可以从这一信息中学习到正常只领用一次,超过一次就异常(向数据学习经验)。
第二,围绕如何通过数据挖掘的手段派生一个参考变量指标,来评估与实际值的偏差是否有异常,来进行异常分析,这对于异常分析是一种即简单又有效的方法。在这个案例里面,主要讲解两种派生参考变量的方法,一个是通过变量的相关性进行参考变量的派生,另一个是通过分类预测,尤其是分类目标变量为数值型的分类预测来派生参考变量。
在这个案例中派生的第一个参考变量是预计田地收入,也就是从实际田地收入与预计田地收入的偏差入手,偏差大的为异常。预计田地收入的派生很巧妙,采用的是相关性的思想,比如工时和收入的问题,如果一个人的收入=工时*时薪,那么对于这个人来说,知道了工时就等于知道了收入。从整个公司来看,员工的工时和收入是强正相关的。因此,派生预计工时和预计收入是一样的,所以本案例是通过三个与田地收入较相关的字段田地的大小、降雨量、田地质量水平相乘派生了一个与田地收入强相关的字段作为预计田地收入。

第二个参考字段预计申请金额的派生也很巧妙,采用的是分类预测算法,使用其预测值作为参考值。看看这个能否想明白其中的道理?
第三,如何通过可视化的方式,来探索一个数值型字段和一个字符型字段的相关性。这是大家需要掌握的,很有效,很好用,也很简单的一个方法。比如在这个案例使用直方图探索收入偏差字段和申请类型的相关性,如下图所示:

第四,通过聚类分析算法来进行异常诊断的方法。该案例介绍的是聚类算法的另外一种灵活运用。采用的是聚类的思想对异常对象进行判断,主要思想是这样的:首先,我们使用聚类算法将对象(每条记录为一个对象)分成两类,其次,计算每一个对象到类中心的距离,距离类中心较远的点即为异常点;
第五个,通过以上四种方法建立了四个模型,四个模型分别从不同的角度对异常进行判断,这就是之前说的异常分析的多模型并行问题。每个模型都会输出名单,最终的可疑名单是四个的总和。
第二个故事:信用卡风险评估
信用风险也可以称为违约风险,是指借款人、证券发行人或交易对方因种种原因,不愿或无力履行合同条件而构成违约,致使银行、投资者或交易对方遭受损失的可能性。
客户是财富来源同时也是风险来源,客户信用风险,如拖欠、赖账、欺诈、破产,都可能会给银行和企业带来巨大的损失。80年代末以来,随着金融的全球化趋势及金融市场的波动性加剧,各国银行和投资者受到了前所未有的信用风险的挑战。银行存在的主要风险是信用风险,这种风险不只出现在贷款中,也发生在担保、承兑和证券投资等表内、表外业务中。如果银行不能及时识别损失的资产,增加核销呆账的准备金,并在适当条件下停止利息收入确认,银行就会面临严重的风险问题。
该数据包括用户的年龄、教育、工龄、本地居住时长、收入、负债率、信用卡负债、其他负债以及用户是否发生过违约等信息。
业务目标:建立信用评估系统,当把信用卡用户的信息导入到该系统时,系统会自动输出这批用户的违约风险及信用得分,为信用卡用户的管理提供决策支持。
数据挖掘目标:建立信用卡用户的信用评估模型,该模型以用户的信息指标为输入,以违约为目标,建立预测模型,该模型可以根据输入指标的值,计算预测值(违约)。
这类场景通常采用分类预测类算法。根据历史的是否违约的特征,模型去总结违约用户的特征并建立违约预测模型。进而可以根据对于每个用户的违约概率的预测,建立信用得分。
这个案例之前也在天善论坛的博客中分享过,大家可以参考:http://ask.hellobi.com/blog/SmartMining/2379。所有的分类预测问题都可以参考这个案例的分析过程,包括欠费分析、客户流失分析、二次购买预测等。
第三个故事:订单违约分析
这一类分析在代理业务应用居多,如医药代理、电子产品代理等。应用于总代对二级代理或者药厂对经销商的风险管控。这一类问题要强调一点,就是精细化的问题。在过去,做代理商的违约分析,可能只需要评估代理商或者经销商的整体信用,给个固定的授信额度就行了。但是目前的商业越来越复杂,单靠这样难以达到风控的目标。比如,一个代理商或者经销商并不是每个订单都会违约,也不是各种类型的订单都会违约。因此,违约的预测,可以精细到对一个订单的预测,在与代理商或经销商整体授信结合,就可以达到更好的效果。
 业务目标 :通过经销商的历史表现、企业概况及其他信息,建立经销商的综合评估模型,评估经销商总体信誉及订单的违约风险。完善企业在经销商分析方面的指标体系,优化数据采集和管理方法。
业务目标 :通过经销商的历史表现、企业概况及其他信息,建立经销商的综合评估模型,评估经销商总体信誉及订单的违约风险。完善企业在经销商分析方面的指标体系,优化数据采集和管理方法。
分析成果:
所有存在授信的场景都会存在违约的风险,而这些场景都可以采用此方法。希望这次分享对大家有所帮助,请多多指教。

